Spark学习笔记
基本概念
Kafka是一个分布式的发布-订阅消息传递系统,其实本质就是一个分布式的日志系统,是实时任务依赖的主流数据源。注意,数据本身同样是存储在hdfs上的。
原理
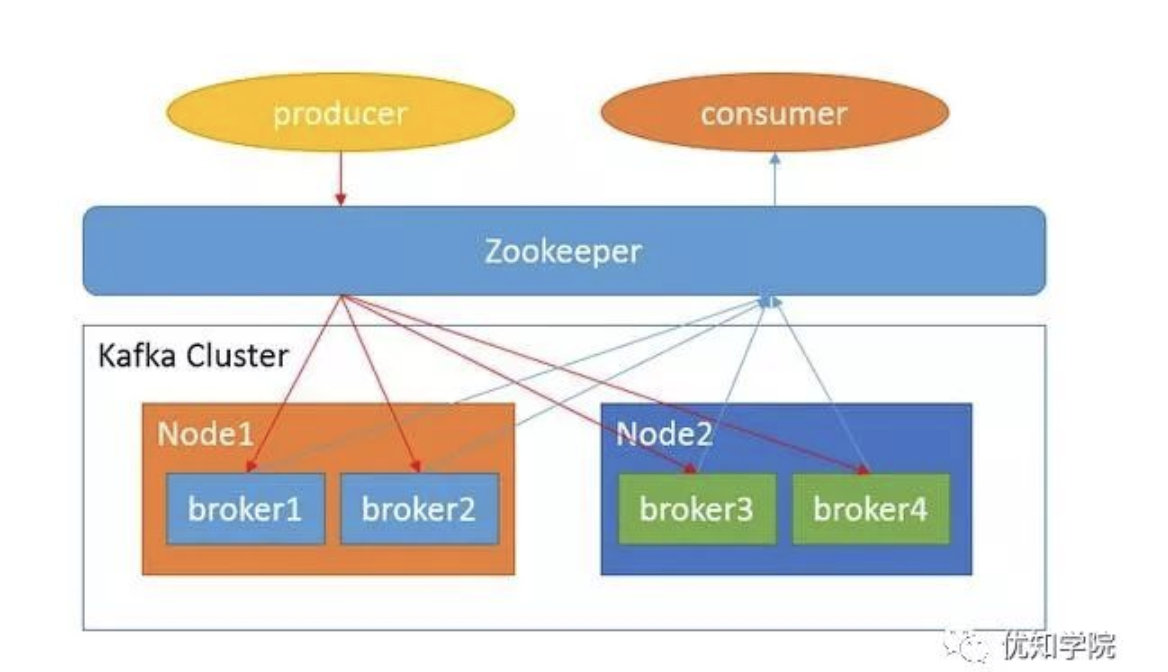
1、话题(Topic):是特定类型的消息流。消息是字节的有效负载(Payload),话题是消息的分类名或种子(Feed)名;
2、生产者(Producer):是能够发布消息到话题的任何对象;
3、服务代理(Broker):一个broker就是一台机器,多台broker组成集群。
4、消费者(Consumer):可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息;
存储
理解存储最主要是理解partition的概念。其实Apache体系里partition的概念都比较类似(比如spark中的partition),都是将数据进行分片,一般分片的逻辑就比如是按照key值来划分,同一个key值分到同一个partition。
Kafka里也是将topic数据进行partition,当然每个partition的数据还是按照顺序写入的,然后将parition分配到不同broker上,partition数目一般设置成broker的倍数,这样能够让每个broker的partition均匀一点。
kafka的partition还会备份,leader作为主要的,follower partition放在其他broker上。
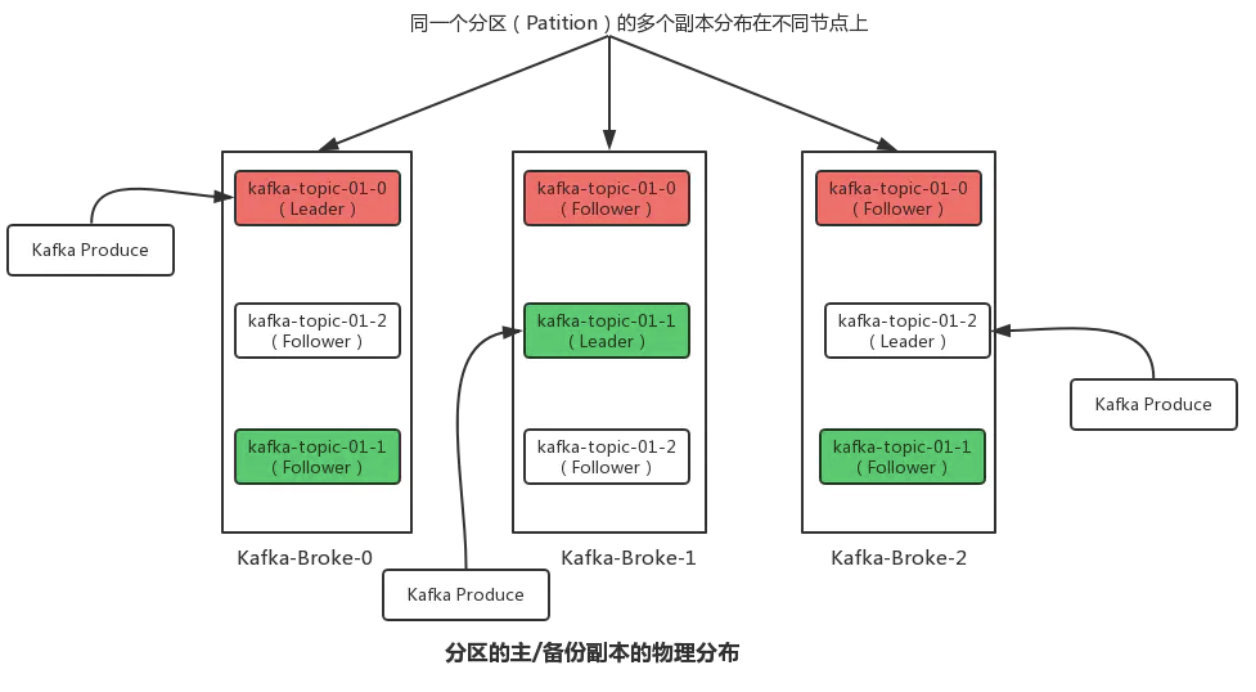
具体存储的日志文件形式是这样的:
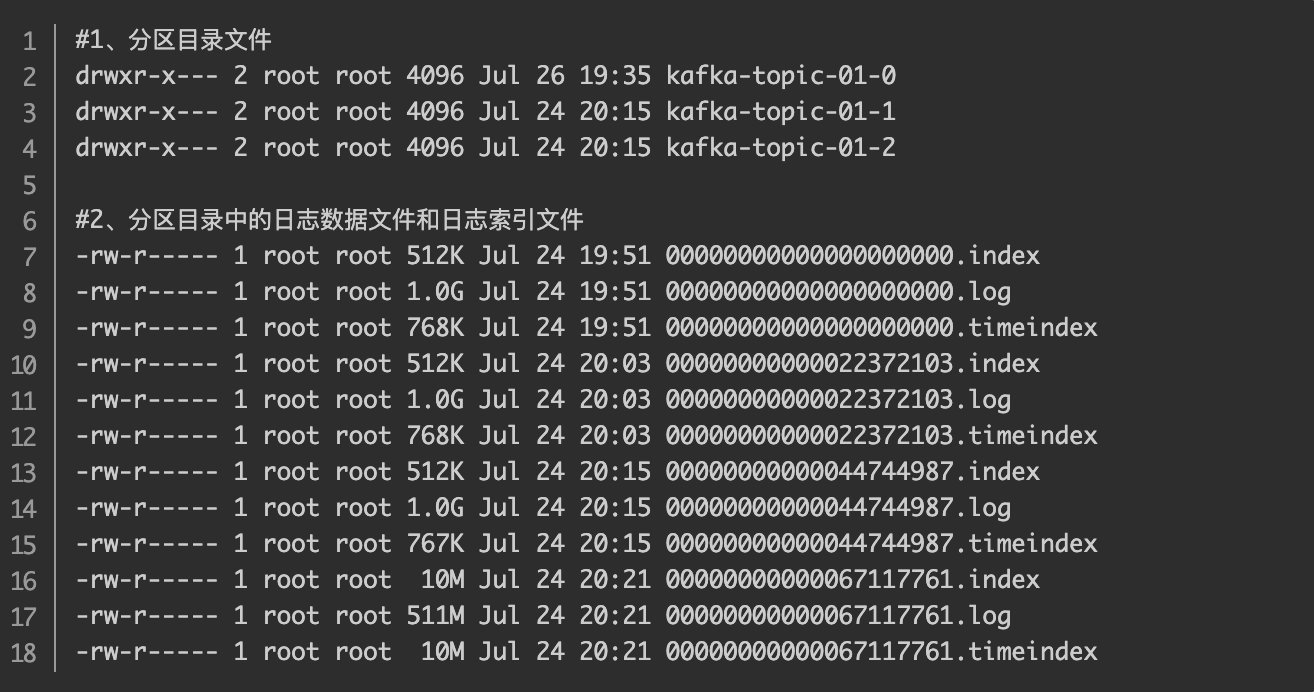
每个topic下的partition都有一个文件夹。文件夹中的文件类型有.log数据文件,.index偏移量索引文件和.timeindex时间索引文件。
日志文件会被分为多个LogSegment文件,一般分段文件是1G。文件名字按照基准偏移量命名。
介绍下具体的三个文件:
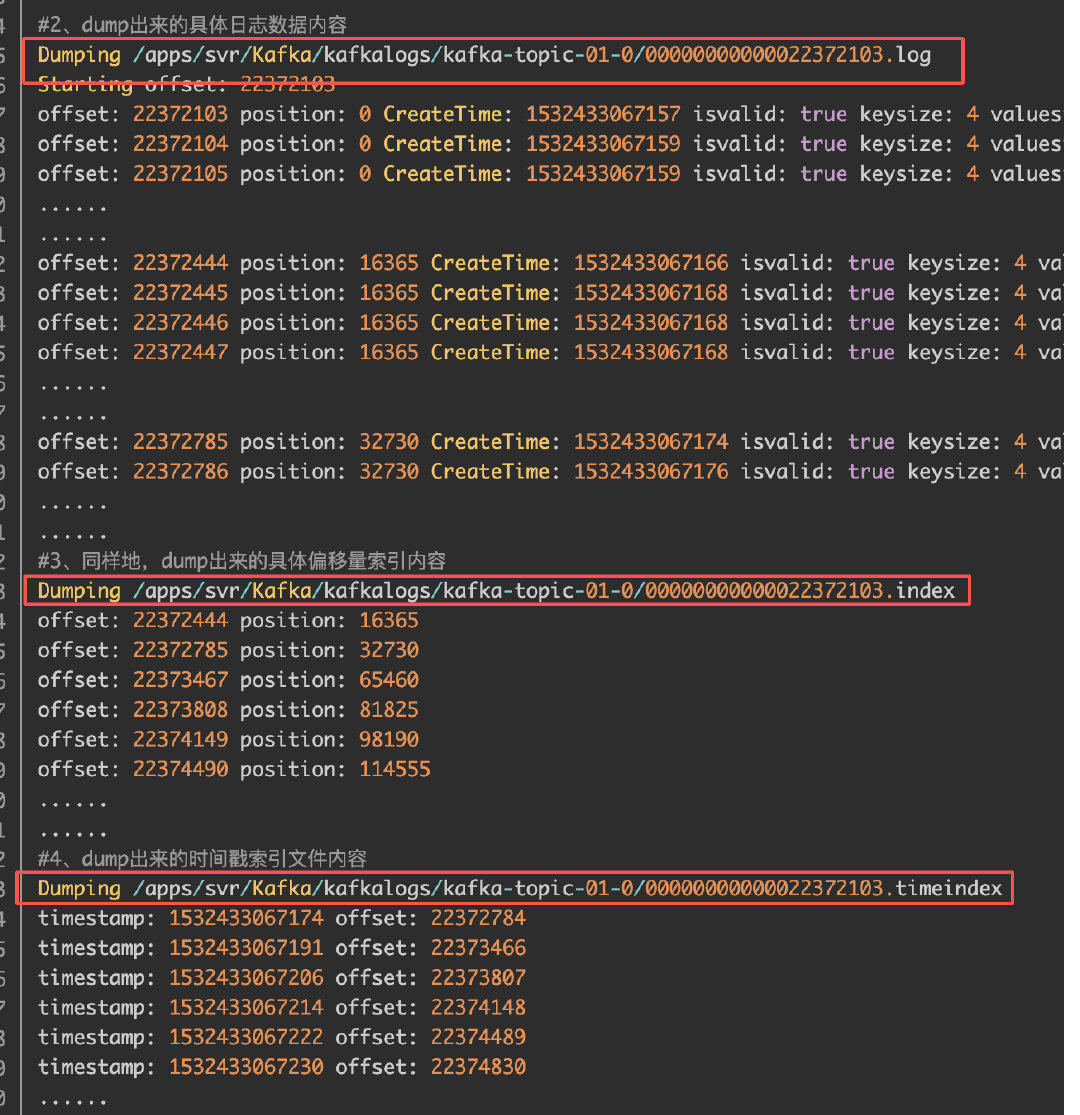
- log文件:真实的日志数据文件,存放消息payload
- index文件:偏移量索引文件,重要的稀疏索引文件。因为如果直接去log文件里顺序查找的话,效率太低。所以现在index文件里做粗筛,定位到大致范围,然后再去log文件里找,大大提升了效率。
- timeindex文件:时间戳索引文件的时间戳类型与日志数据文件中的时间类型是一致的,索引条目中的时间戳值及偏移量与日志数据文件中对应的字段值相同,Kafka也提供了通过时间戳索引来访问消息的方法。
Spark学习笔记
http://levylv.github.io/2020/11/10/大数据/Kafka/Kafka学习笔记/