Flink学习笔记
基本概念
Flink是一个分布式的流式数据处理框架,目前很多公司都开始用flink来处理流式任务(对,说的就是我司)。在Flink之前,其实我们已经有spark streaming和storm来处理流式任务,为何还要flink?下面就说吞吐量和时延上说下flink的优势,主要讲一下基本原理和容错机制。
流框架
- Naive streaming: storm和flink都是naive streaming处理,这类引擎中所有的data在到来的时候就会被立即处理,一条接着一条(HINT: 狭隘的来说是一条接着一条,但流引擎有时会为提高性能缓存一小部分data然后一次性处理)。
- Micro-batch:spark streaming是批处理的。数据流被切分为一个一个小的批次, 然后再逐个被引擎处理。这些batch一般是以时间为单位进行切分,单位一般是‘秒‘。
显然, storm和flink因为是naive streaming,他们的时延性能要远远优于spark streaming。
- spark streaming:秒级别
- storm:几十毫秒级别
- flink:百毫秒级别
但相对的,吞吐量上spark streaming是最大的。
容错机制(Fault Tolerance)
先讲下三个性质:
- at-most-once:就是说数据只发一次,成不成功都有可能。所以这种分发方式成本最低,吞吐量和时延都很好,但是数据可能丢失,可靠性不高。
- at-least-once:数据如果不发送成功,就会多次重发尝试,需要发送端做处理,且接收端有ack机制。这种方式可能会造成数据的重复问题。
- exactly-once: 保证数据有且只有一次,接收端要做数据的去重。
Spark streaming
spark依赖checkpoint机制来进行容错,只要batch执行到doCheckpoint操作前挂了,那么该batch就会被完整的重新计算。spark可以保证计算过程的exactly once(不包含sink的exactly once)。
Storm
storm的容错通过ack机制实现,每个bolt或spout处理完成一条data后会发送一条ack消息给acker bolt。当该条data被所有节点都处理过后,它会收到来自所有节点ack, 这样一条data处理就是成功的。storm可以保证数据不丢失,但是只能达到at least once语义。此外,因为需要每条data都做ack,所以容错的开销很大。
Flink
flink使用Chandy-Chandy-Lamport Algorithm 来做Asynchronous Distributed Snapshots(异步分布式快照),其本质也是checkpoint。如下图,flink定时往流里插入一个barrier(隔栏),这些barriers把数据分割成若干个小的部分,当barrier流到某个operator时,operator立即会对barrier对应的一小部分数据做checkpoint并且把barrier传给下游(checkpoint操作是异步的,并不会打断数据的处理),直到所有的sink operator做完自己checkpoint后,一个完整的checkpoint才算完成。当出现failure时,flink会从最新完整的checkpoint点开始恢复。
flink的checkpoint机制非常轻量,barrier不会打断streaming的流动,而且做checkpoint操作也是异步的。其次,相比storm需要ack每条data,flink做的是small batch的checkpoint,容错的代价相对要低很多。最重要的是flink的checkpoint机制能保证exactly once。
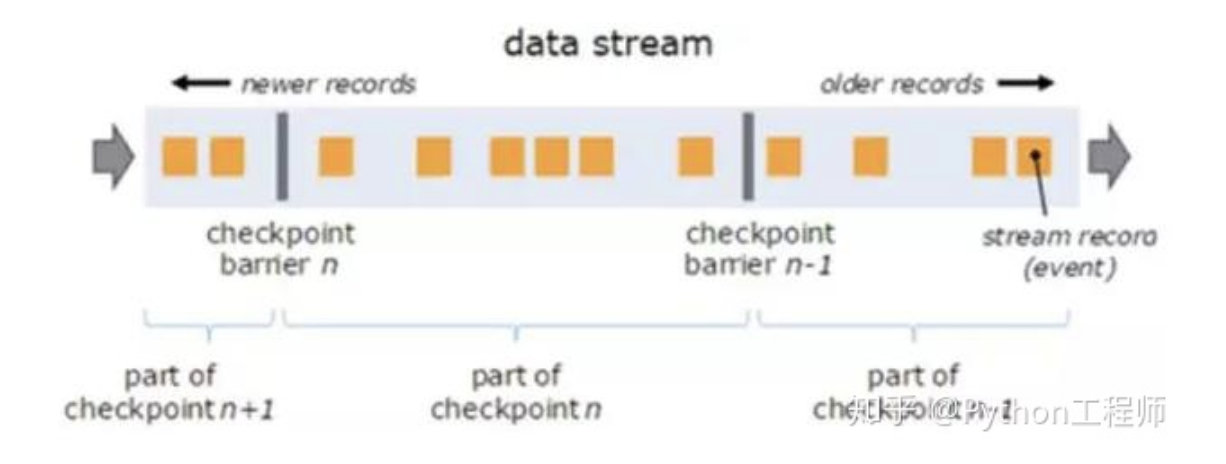
显然,storm的容错机制需要对每条data进行ack,因此容错开销对throughputs影响巨大,throughputs下降甚至可以达到70%。
flink的容错机制更加轻量,处理开销少,因此相比于storm来说,flink可以达到更大的吞吐量。
最终性能
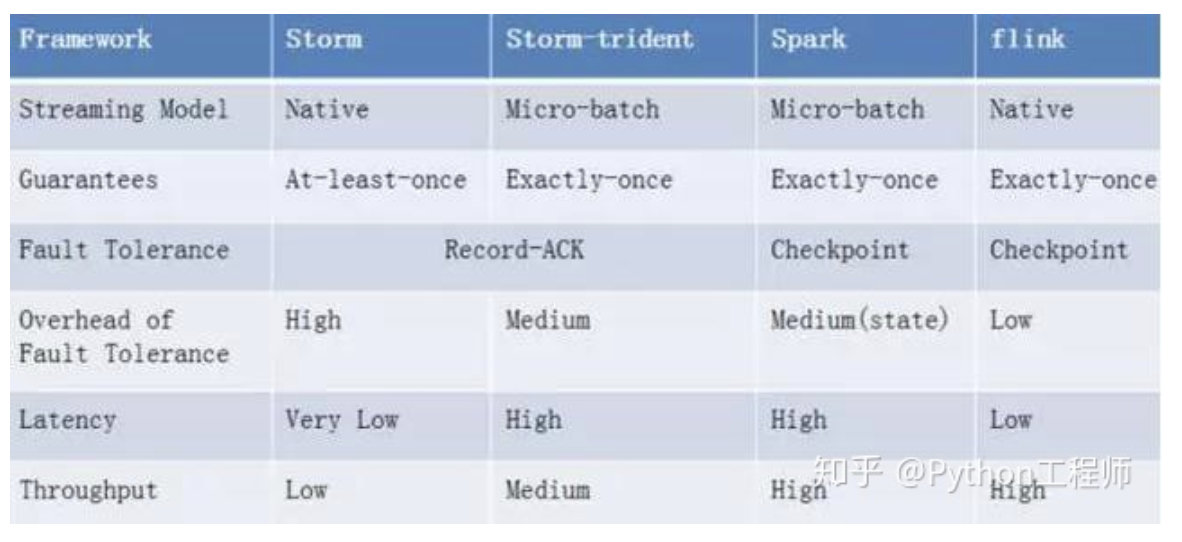
从吞吐量和时延性能的综合来看,flink是最好的。