NAS系列文章解读
NAS最近几年是AutoML领域比较火热的方向,主要是神经网络结构的自动搜索。最近看了几篇NAS文章,下面按照发展历史做个总结。
参考博客:
一、NAS的提出
文献:《NEURAL ARCHITECTURE SEARCH WITH REINFORCEMENT LEARNING》
本质上就是确定通过一个rnn的controller,来生成神经网网络的结构。
例如卷积神经网络,那么无非就是要确定卷积核的数目、高、宽,stride的高和宽,也就是利用controller来生成这个五个参数。
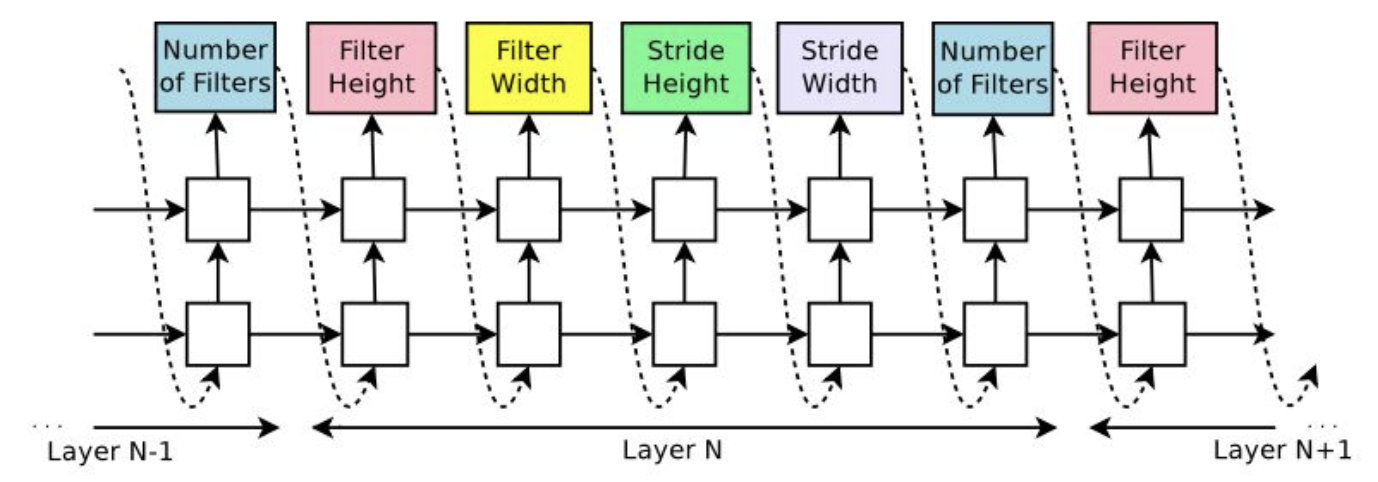
controller得到5个参数的概率,然后通过sample得到网络结构,再基于该网络结构得到其在验证集上的accuracy,再利用该accuracy去更新controller的权重。这一步就类似于强化学习的policy network,我在之前的博客中也有介绍,其实本质上就是一种优化算法,当目标变量的函数未知的情况下,优化目标的一种优化算法,这里是最大化accuracy,在无法知道结构和accuracy的关系,用神经网络去逼近。
关于网络的深度,还是靠人为去设置的,这里的话是每sample 1600次,就将深度加深2。所以其实这个计算成本是很高的,每次深度加深,又要重新计算该模型结构的精度…文章最好的cifar-10上的最佳cnn结构是这样的:
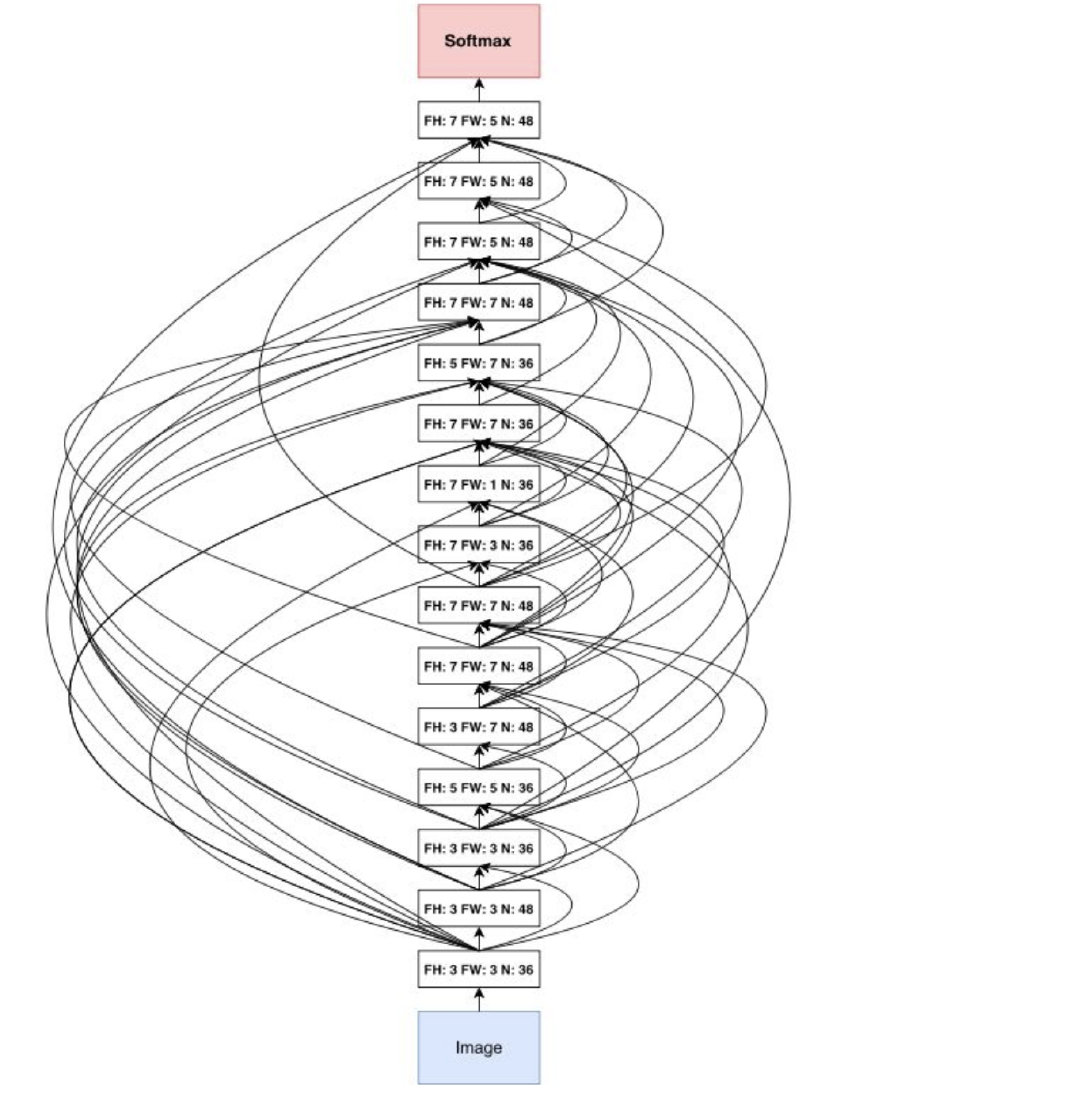
二、NAS的改进
文献:《Learning Transferable Architectures for Scalable Image Recognitio》
原先NAS的缺点就是复杂度太高,每次都要评估生成的整个网络结构,因此本文提出一种思想:其实在经典的VGG、Inception等结构中,往往都是反复利用一种卷积结构做堆叠生成的,因此我们只需搜索这种卷积结构的最优解就行。
文章提出了Normal Cell和Reduce Cell,整个网络结构就是这两种cell的重复。注意,整个网络重复的次数N,还是人为拍的。
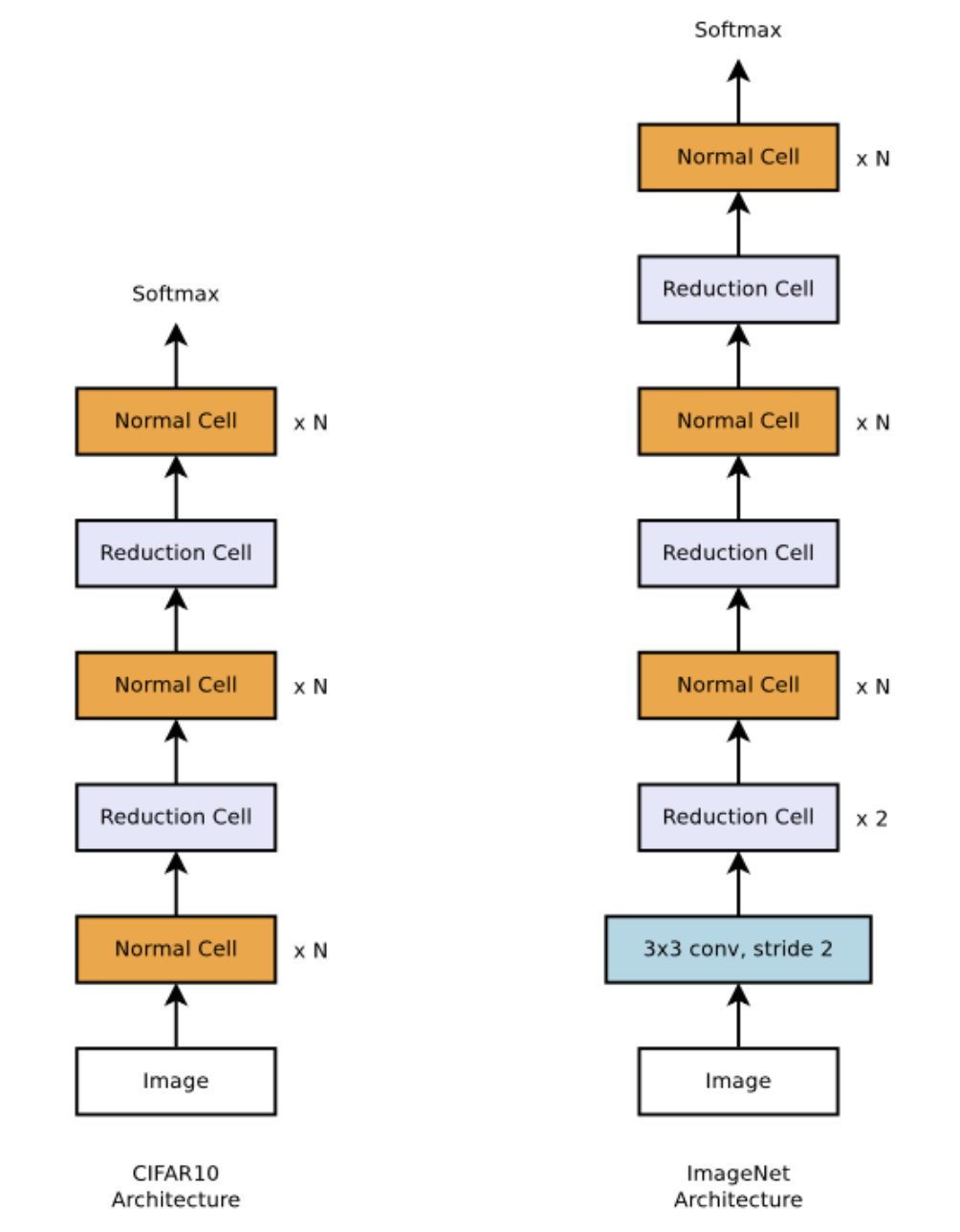
我们只需搜索这两种cell的结构,搜索过程是这样的:
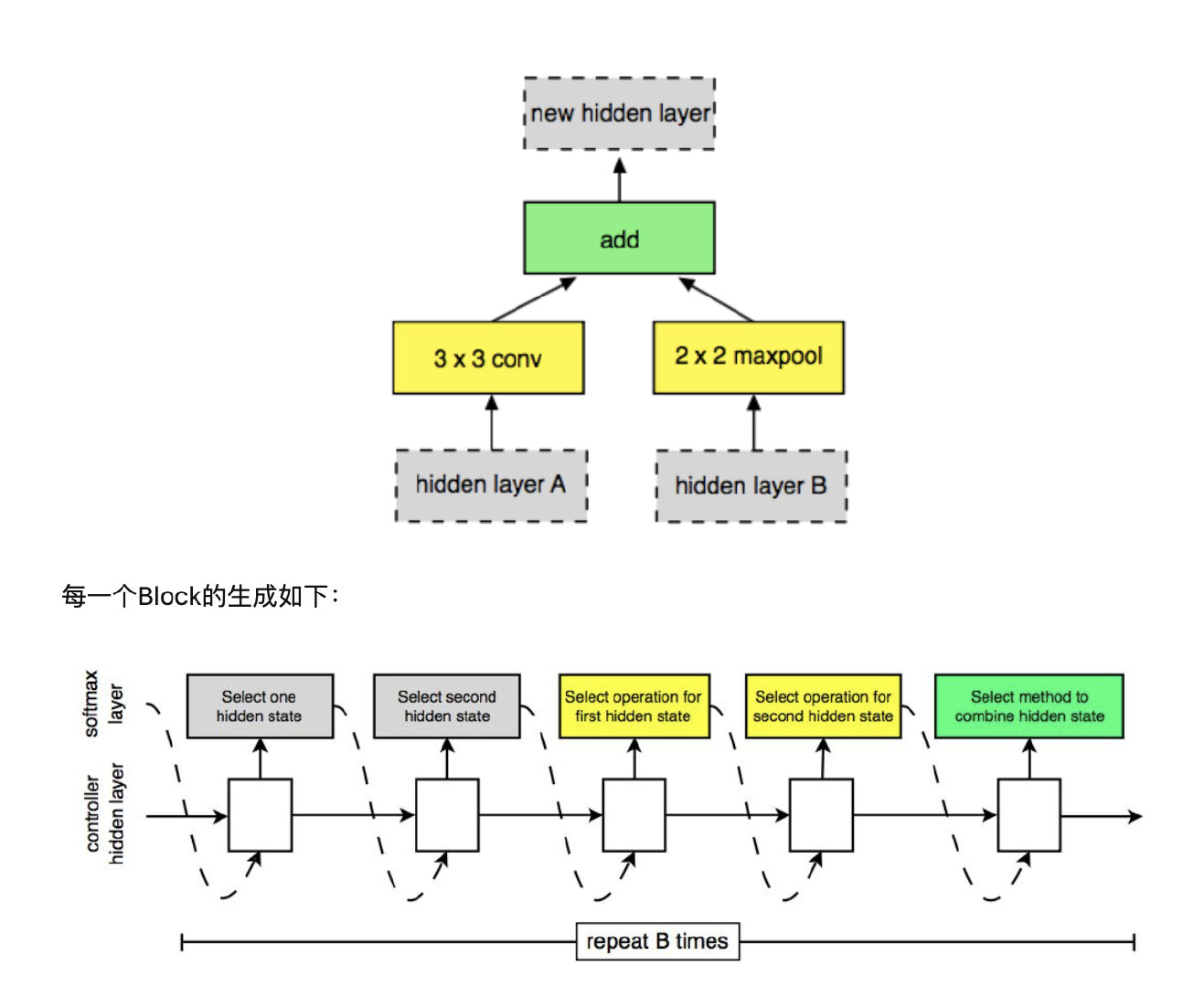
假设一个Cell里有B个block,每个block生成步骤为:
- 从hi和hi-1或上一步中得到的隐含状态中选择一个作为输入一。
- 从从hi和hi-1或上一步中得到的隐含状态中选择一个作为输入二。(可以与第一个一样)
- 从操作集合中选择一个操作应用在输入一上。
- 从操作集合中选择一个操作应用在输入二上。
- 选择一个方法将第三步和第四步的结果合并。
三、PNAS
文献:《Progressive Neural Architecture Search》
即使改进后,搜索一个神经网络结构,我们依然需要花800个GPU花4天的时间,我们可以进一步的降低复杂度。PNAS的思想是更为贪心的搜索。假设B=5,总共的复杂度为:
对于第一次运行生成方法,只有两个输入,因而,选取两次,得到2x2种可能。有八种operator,选取两次,得到8x8中可能,因而第一次运行该方法的空间是22x82。而对于第二次运行生成方法,operator选择的可能性没有变化,但因为上一步有一个隐含状态输出,所以输入变成了3x3中可能。以此类推,五次运行生成算法的搜索空间是:
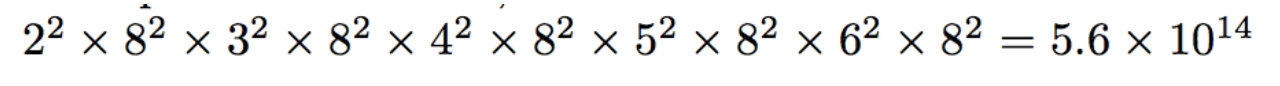
而PNAS的话,我们第一步得到2^2 * 8^2 = 256种可能后,就用controller生成网络结构进行256种可能的搜索,找到top k的最优结构。然后之后第二步,就基于这top k结构来搜索,这样相当于进行了剪枝,减少了大量的计算空间。
整体步骤:
完全训练生成算法第一步的所有可能的候选(256 / 2 = 136个,因为对称性)
训练启发式搜索算法
对于生成算法的后面几步的每一步:
- 取得所有候选结构
- 预测候选结构在某数据集上的准确率,按照准确率排序。
- 取出准确率最高的top-K模型结构,进行训练。
- 训练启发式搜索算法
PNAS提升:模型数目减小为五分之一,而总速度降低为八分之一。
四 、ENAS
文献:《Efficient Neural Architecture Search via Parameter Sharing》
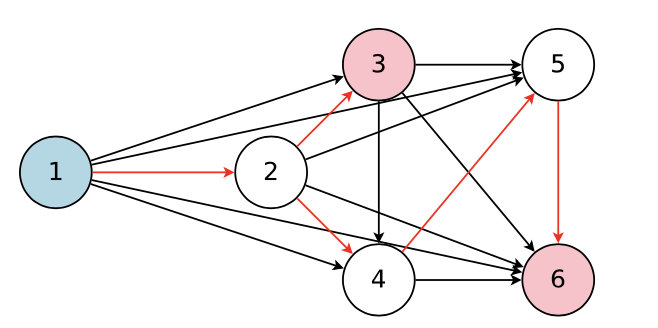
最后是目前最常用的方法ENAS,ENAS利用参数共享的思想把复杂度提升到了原来的千分之一。ENAS的思想是把要搜索的结构想像成一个node,所有的node构成一个大的DAG,而我们要搜索的可能就是一个子图结构,但是所有node之间的权重是共享的,不需要每搜索一次子图,就重新计算子图node之间的权重。

之前的NAS是对候选子模型逐个从头训练,事实上子模型的结构许多都是相似的,所以许多Wi,j (第i个节点与第j个节点的权重矩阵) 是可以复用的,没有必要从头开始训练。这样的共享权重在文中被称作shared model。
最终我们要搜索的是子图,也就是红线流向:
再讲一下ENAS的训练,显然我们需要训练两个参数:
- 共享权重参数
- controller的参数
整个训练过程是这样的:
- self.train_shared() 。在模型架构固定的情况下,基于训练集,更新和共享内部参数权重Wi,j,使得内部权重得到更好收敛。
- self.train_controller() 充分使用共享的内部权重,从controller RNN中抽样出一些候选子模型,在这些模型中选择在验证集上表现最好的架构,继续步骤1的计算。
相当于以前的NAS我们通过self.train_controller采样得到模型结构,然后每个模型各自训练,最后平均得到accuracy来更新controller。而ENAS的话我们采样得到模型结构后,不需要进行训练,直接基于当前共享权重,得到这些模型中表现最好的架构。然后再基于该模型架构,更新共享权重。
五、DARTS
文献:《DARTS- Differentiable Architecture Search》
依然是基于参数共享的理念,但是以往我们都是通过controller来控制node之间的信息流向,但是DARTS通过权重系数alpha直接来控制,不再需要controller:
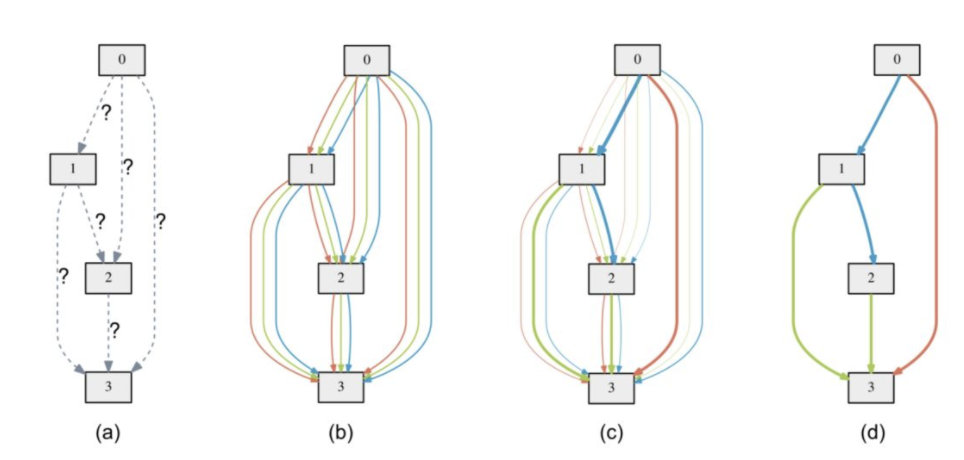
所以DARTS算法的流程是:
对每个模型结构选择的地方,建立一个mixed operation。这个mixed operation有参数a(每个Node(i, j)都有一个operation维度总数的系数向量),作为权重。模型本身的参数我们设置为w
当模型还没有收敛时,做:
- 更新mixed operation的模型结构参数a。使用gradient descent:grad(a, Lvalid(w(a), a)). 这里的w指在a结构下,训练到converge之后最佳的模型本身的参数w
- 对模型本身的参数w做gradient descent。
如果像之前Multi Trials AutoML的方式,每次求解最后converge最佳参数w代价很高。类似ENAS,我们用单步优化的w来近似最优的w,这样效率更好。因此对a的gradient变为:grad(a, Lvalid)(w - epsgrad(w, Ltrain(w, a), a)。实际上因为之后对w也会做gradient descent,这里直接用first order approximation即可,eps = 0,直接变为grad(a, Lvalid)(w, a)。这样每次计算量大大降低。

总结
其实上述这些神经网络架构搜索,也不是完全的智能搜索,还是需要人为来确定一个搜索空间,然后基于某类优化算法来求解优化问题罢了。优化算法可以有很多,比如暴力搜索、random search、贝叶斯优化、DQN、粒子群、policy network等等。像这种我们不知道x(网络架构)和y(模型准确度)这种关系的优化,用policy network的方法是一种很直观的想法。