最近在看NAS(neural architecture search)的论文,里面讲到了强化学习的policy network,然后我就研究了下这个东西,发现是个蛮有意思的概念,确实和nas有共同之处。有意思的点主要其实是在loss function的设计上,下面详细讲下我的理解。
正常来讲,我们做一个Neural Network来解决Classification or Regression task, loss function往往就是涉及一个真实label和一个esitimated label,也就是NN预测一个概率,然后拿真实的概率去做cross entropy或者等价的最大似然函数作为loss function。但是对于强化学习任务,我们通过NN预测一个动作的概率 $\pi(a|s, \theta)$,但是无法知道这个动作的真实label是什么?那要怎么来设计Loss function呢?
其实想法也很intuitive,Policy Network设计一个评价指标$f(a, s)$,你也可以认为是做出这个动作a之后取得的reward,然后这个loss function为:
其实你仔细一看,发现对比正常loss function - $\sum p(x) log{\hat{p}(x)}$,无非就是把真实label的概率换成$f(a, s)$罢了。这样的loss function其实本质上就是等价于 最大化评价指标$f(a, s)$,推到过程如下:

最后,衍生到NAS上,其实本质和Policy Network是一样的。NAS里我们想要得到一个神经网络结构的概率,然后评价指标,就是用这个结构得到其在验证集上的精度。
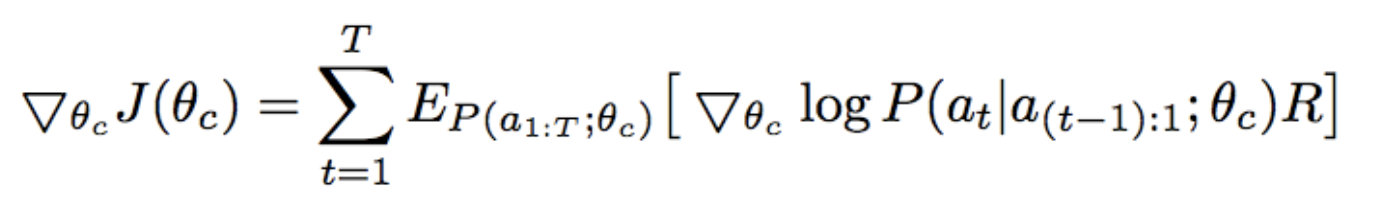
http://levylv.github.io/2020/10/30/深度学习/关于policy network/