Attention和Transformer
一、背景
Attention是目前最热的深度学习方向,最开始从NLP领域的机器翻译方向发源,到如今百花齐放到各个领域,包括推荐搜索,计算广告等等,万物皆可embedding,万物皆可attention,因为attention的本质就是为了更好的做embedding。
本篇文章按照attention发展的顺序来阐述:
- Seq2Seq模型
- Attention机制
- Transformer的Self-Attention
- Bert
二、Seq2Seq模型
最开始做机器学习的时候,我们用rnn模型做encoder-decoder,encoder输出最后的隐层向量,然后decoder逐个输入进行解码。
对于encoder-decoder的方式,要注意训练和预测的不同:
- 训练:decoder的输入是当前单词的embedding
- 预测:decoder的输入是上个rnn的输出
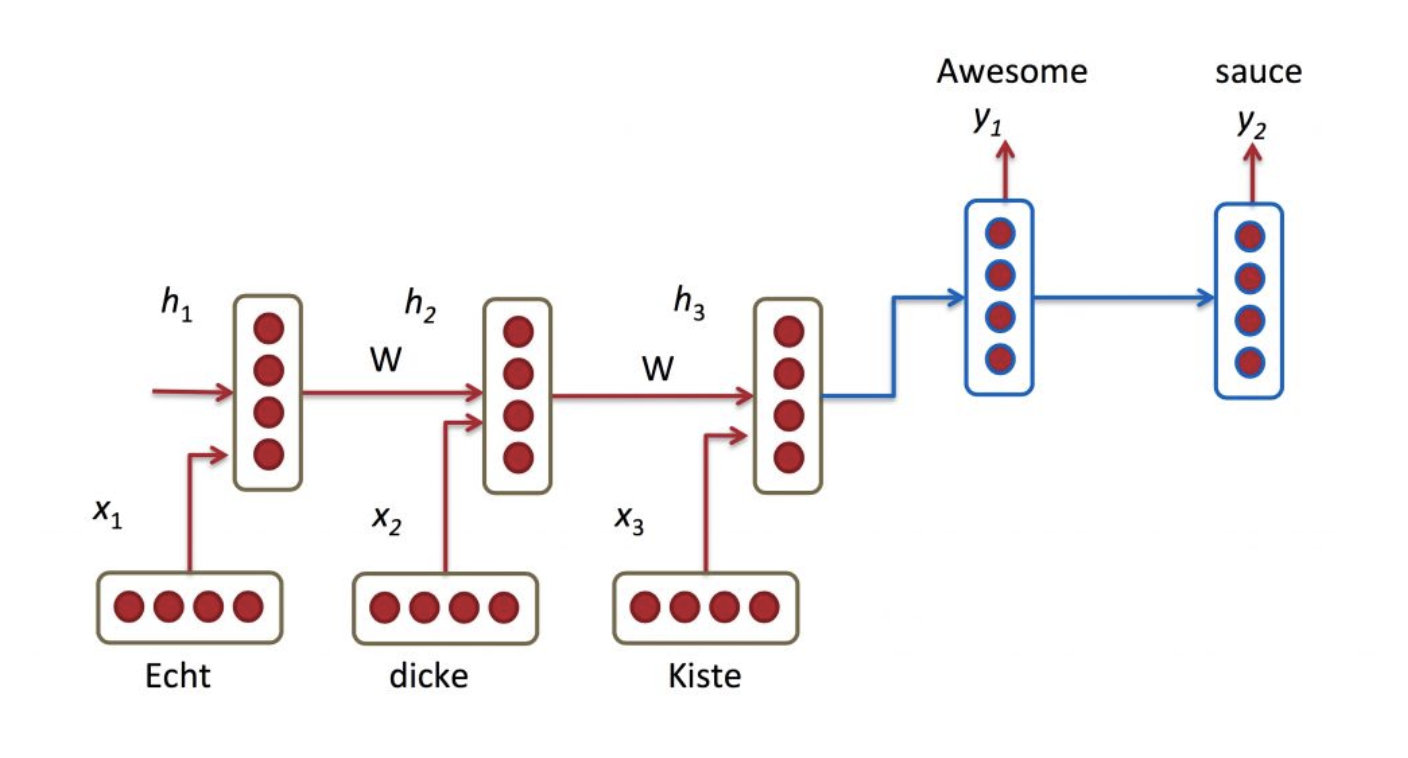
对于这种Seq2Seq的方式,很明显最大的问题就是将encoder压缩在了最后一个rnn输出上,RNN机制实际中存在长程梯度消失的问题,对于较长的句子,我们很难寄希望于将输入的序列转化为定长的向量而保存所有的有效信息,所以随着所需翻译句子的长度的增加,这种结构的效果会显著下降。
三、Attention机制
基于Seq2Seq,学术界提出了attention机制:
- 不用将encoder的最后一层喂给decoder。
- 在decoder的时候,除了当前的输入外,我们还会附加一个context_vector,这个vector利用上一层的隐层输出与encoder做attention得到,这样的话就充分得利用了encoder里每个词的信息。

参考博客。
详细讲讲attention的做法,其实本质上就是生成Q,K,V三个向量:
- Q是查询向量,一般就是我们要查的item生成的向量
- K是被检索向量的key
- V是被检索向量的value,一般而言K和V都是被检索item生成的向量
- 具体计算方式如下:本质上就是Q和K点积先生成Q在每个被检索item的权重,然后对每个被检索item的V进行加权求和,得到检索item最终的向量。
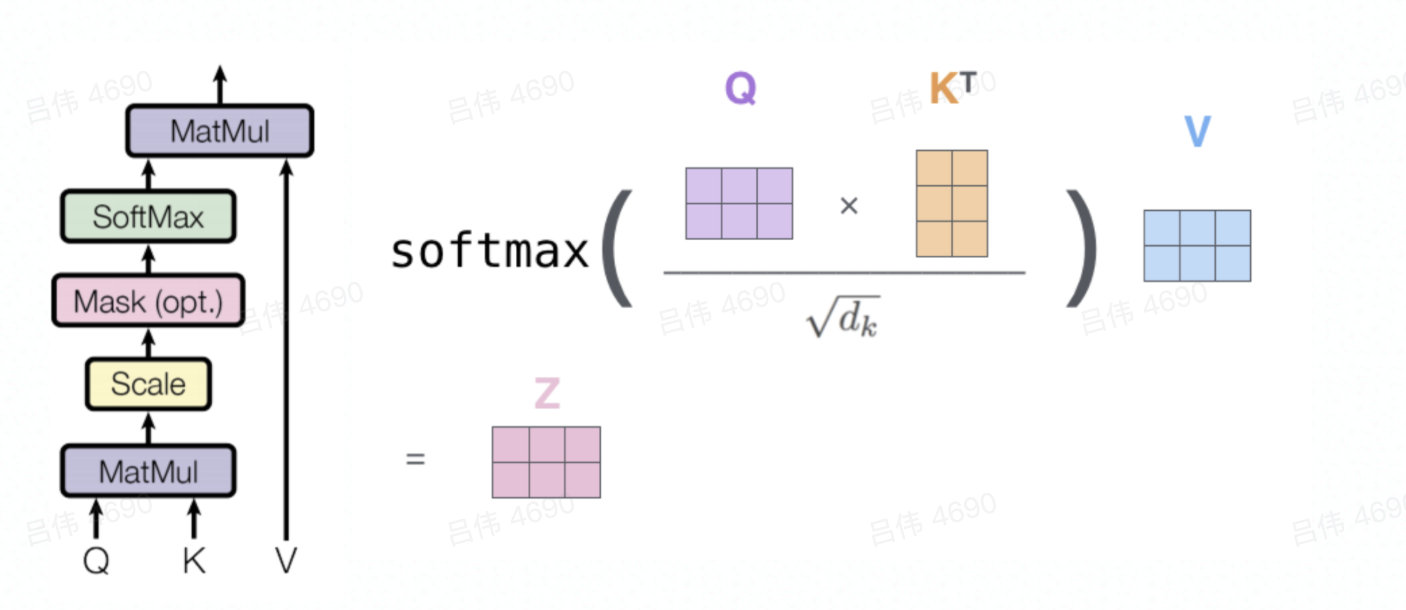
对于encoder-decoder模型,K和V就是encoder每个rnn单元的隐层向量,Q就是decoder的前一个rnn单元的隐层向量。
这里除以根号dk的原因:
- 以数组为例,2个长度是len,均值是0,方差是1的数组点积会生成长度是len,均值是0,方差是len的数组。而方差变大会导致softmax的输入推向正无穷或负无穷,这时的梯度会无限趋近于0,不利于训练的收敛。因此除以len的开方,可以是数组的方差重新回归到1,有利于训练的收敛。
四、Transformer的Self-Attention
谷歌在Attention is All you need首次提出来transformer模型,其中就是提出了self-attention的概念,本质上就是代替了原先的rnn单元,因为rnn单元是串行训练的,无法并行化,效率很低,而且无法充分利用上下文的信息,self-attention就是当前的item同时产生Q,K,V,然后不同item之间做attention,所以这也是为什么叫self-attention。
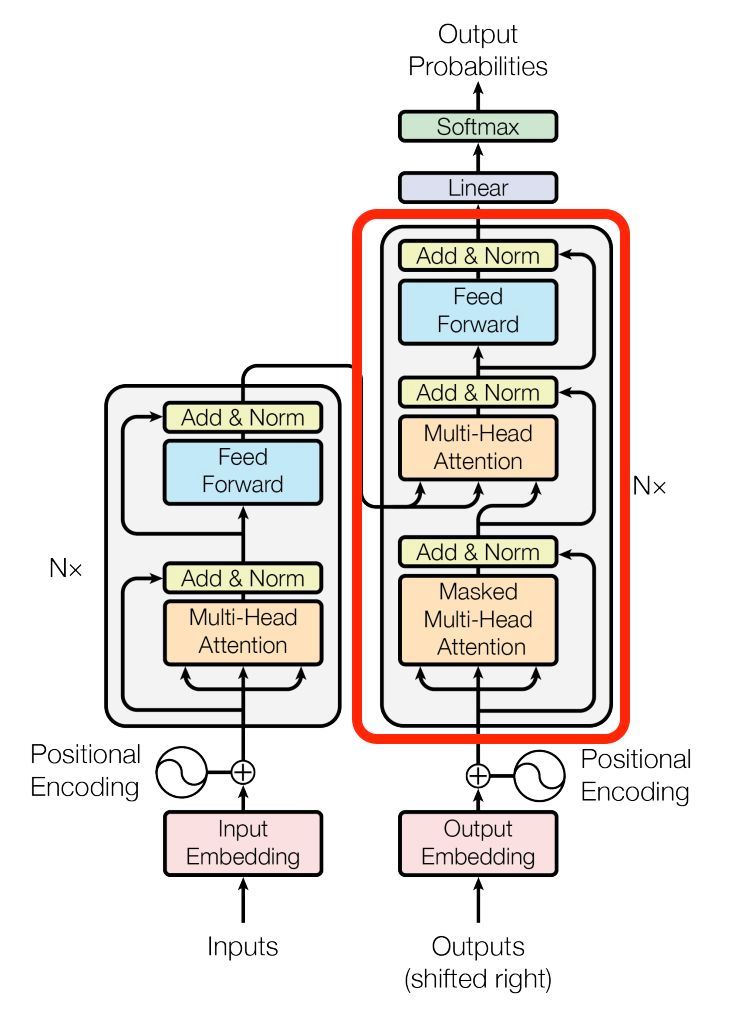
下图是transformer的架构,也是有encoder-decoder组成的,其中最重要的就是multi-head attention部分。
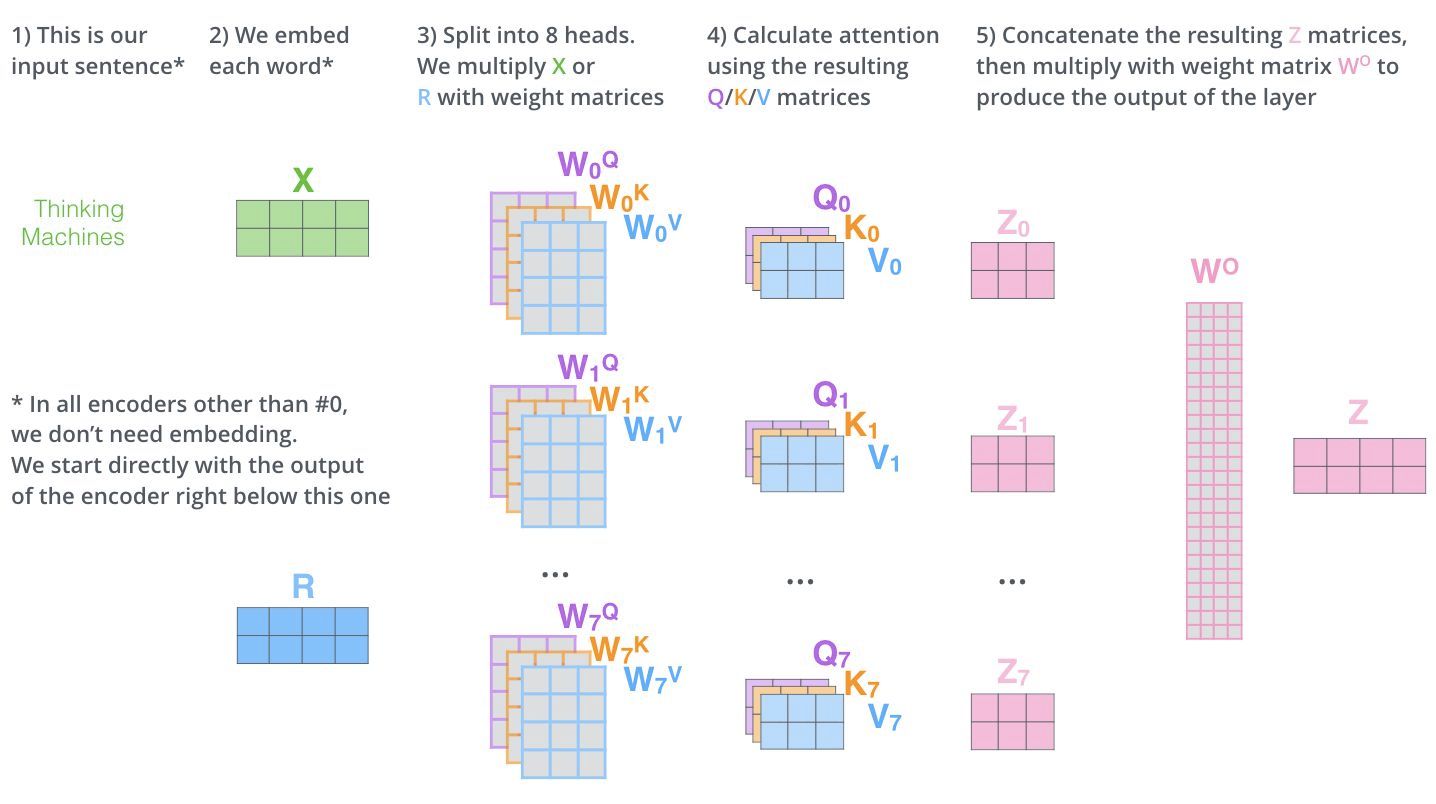
Multi-head attention的架构图如下,所谓的multi-head就是用了多个QKV,最后concatenate之后,再经过一个线性变换,最后生成和输入一样维度的向量,中间Q,K,V的向量维度是自定义的。
- 一个multi-head attention单元,每个item的输入embed维度和输出embed维度是一样的,类似经过了一个变换单元。
encoder的话就是就是经过了N个multi-head attention单元,输出每个item的隐层向量
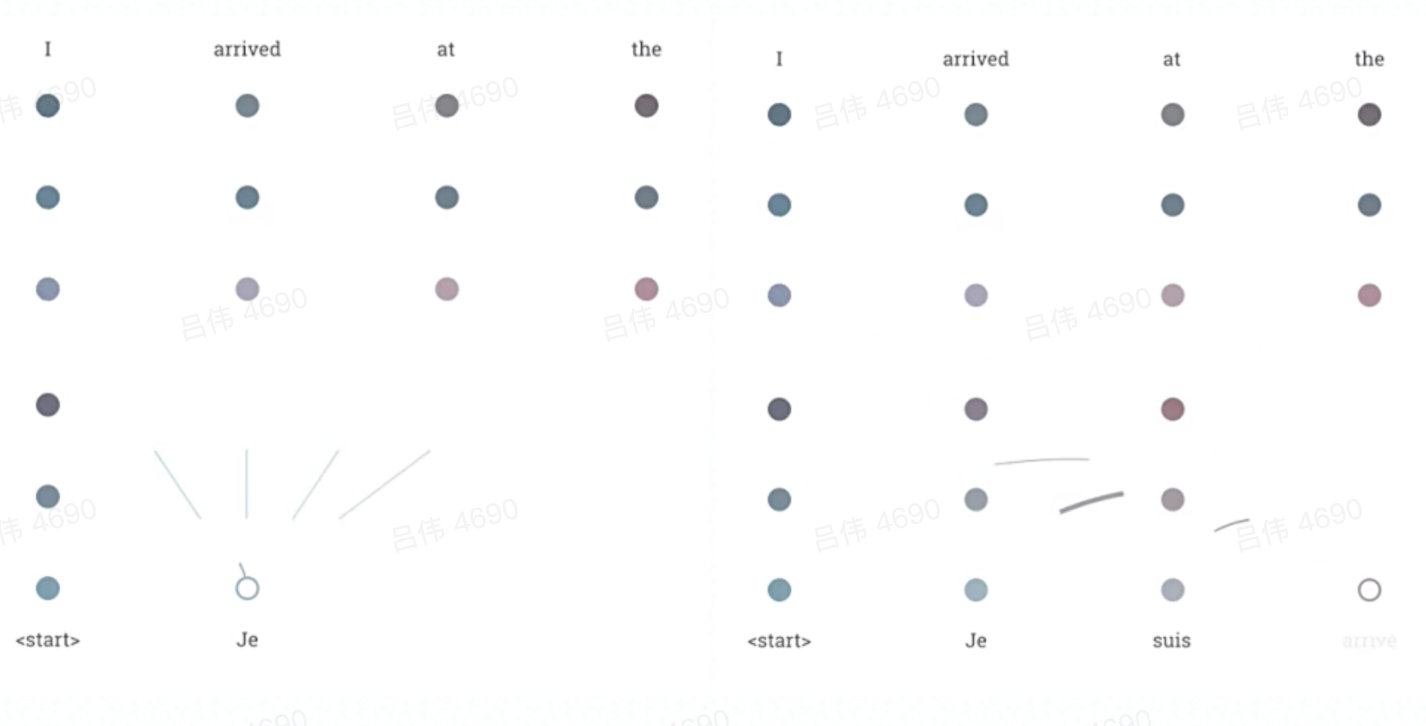
decoder的话有所不同,首先是生成当前item的输入向量,这个也是经过multi-head attention单元,但是会有个mask,就是只用当前item之前的item做attention,最终生成当前item的输出向量后作为Q,而K和V则是encoder的输出,这样再经过一个multi-head attention单元,生成当前item的最终输出向量,可以看下面这个图片示意:
五、Bert
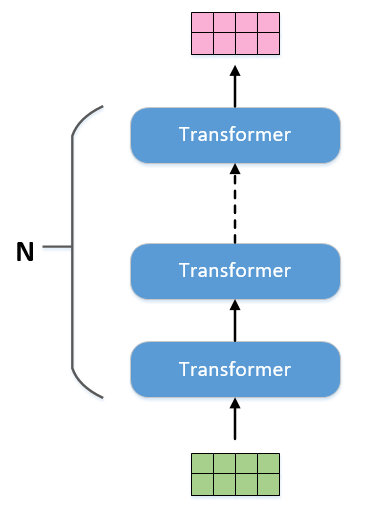
Bert就是transformer的encoder部分进行更多堆叠的结果,如下图所示。当输入有多少个embedding,那么输出也就有相同数量的embedding,可以采用和RNN采用相同的叫法,把输出叫做隐向量。在做具体NLP任务的时候,只需要从中取对应的隐向量作为输出即可。
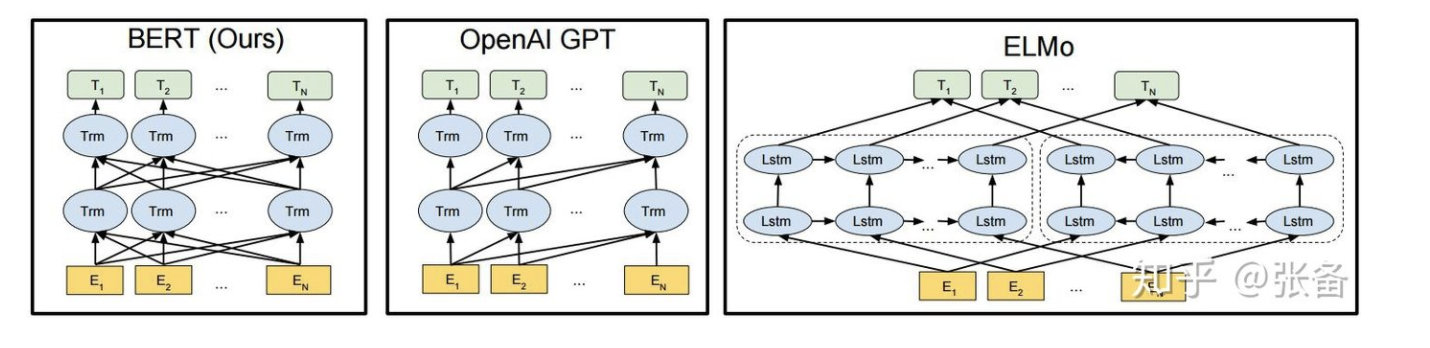
bert本质上即使一个大型的预训练模型,然后拿预训练的词向量放到特定的nlp任务里做微调,就可以得到非常好的效果。和bert类似的还有GPT,ELMo,区别如下图:
bert的预训练方法有如下几种:
- masked language model:在一句话中mask掉几个单词然后对mask掉的单词做预测
- next sentence prediction:判断两句话是否为上下文的关系
- 这两个训练任务是同时进行的,最后做加权loss
六、代码参考
具体transformer encoder的写法,可以参考这个代码:这个代码是BST的写法,bst就是对用户行为序列做multi head self attention。
1 | |