Online Learning中的优化器
今天详细看了下推荐广告系统的online_learning,顾名思义,online_learning就是在线输入样本,更新模型,尽可能做到分钟级/小时级的模型更新,其实关键就是几个问题:
- 模型怎么学习?
- 怎么降低模型复杂度,保证inference的低延时?
参考博文 : FTRL 不太简短之介绍
模型怎么学习?
这个其实很简单,其实要求我们可以基于在线输入的样本,进行权重参数更新,基于类似随机梯度SGD的思想即可。
怎么降低模性复杂度,也就是稀疏特征?
答案自然是L1正则。但是问题来了,如果用SGD,我们很难保证L1正则的效果-即得到稀疏解。理由是:

即使全局梯度满足L1正则的稀疏条件,但是随机梯度下降因为其随机性,无法保证每次都能满足稀疏条件,所以即使用L1正则,还是难以得到稀疏特征。
替代SGD的方法
总体而言,其实就是两个步骤:
- 先按照次梯度更新权重(为什么是次梯度?因为L1正则在x=0的地方不可导!所以是次梯度)
- 然后对梯度进行投影
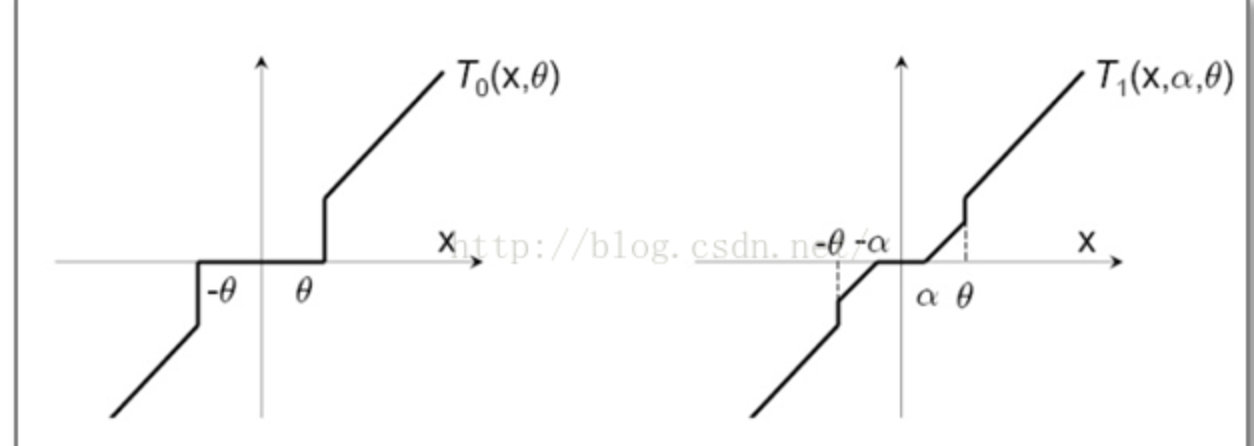
简单截断法
投影方法,就是直接设阈值,对梯度进行截断:

Truncated Gradient
投影方法,就是分段截断:

上面两种方法的图解:
FOBOS
投影方法,就是求最优化闭式解。

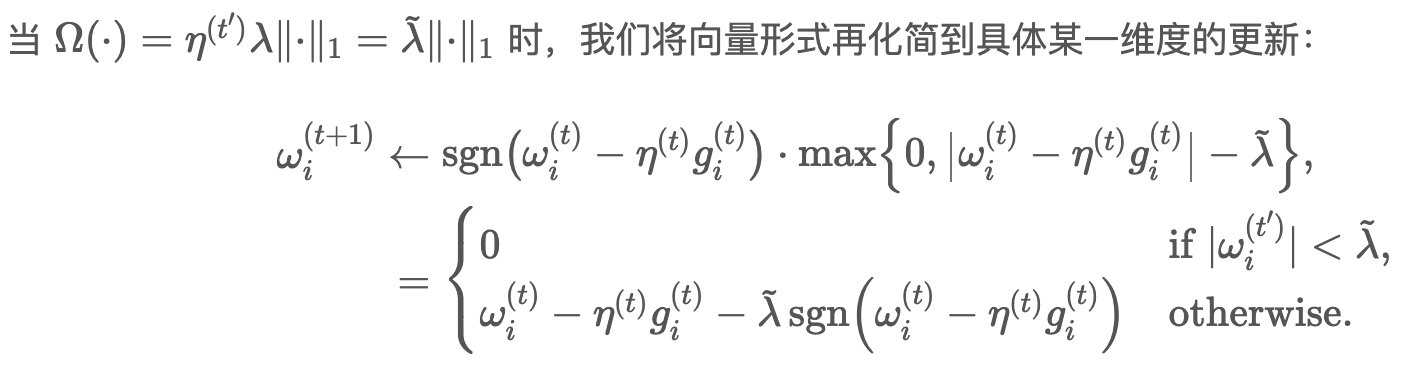
RDA (Regularized Dual Averaging)
改进在于,利用前面t次累加的梯度。和 FOBOS 及之前的截断方法比较,RDA 最大的差别在于丢弃了梯度下降的那一项,换成了梯度的二次平均值。
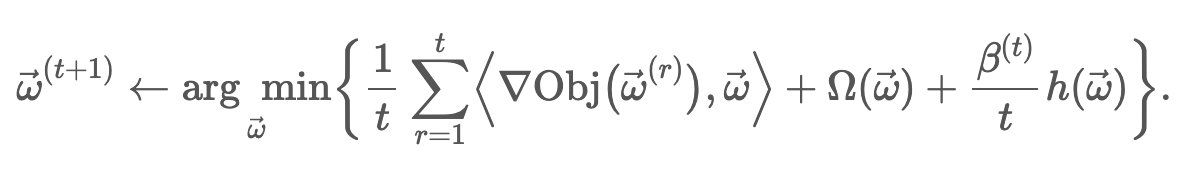


FTRL (Follow The Regularized Leader)
也是我们目前通常在用的方法,结合了FOBOS和RDA两者的优势。

Online Learning中的优化器
http://levylv.github.io/2022/08/10/搜推广/Online Learning中的优化器/