后端技术栈
微服务
一种将整个后端服务,按照领域、模块分解为若干独立小应用的一种架构方式。微服务有如下特点
- 服务可以单独编写、发布、测试、部署,相比于所有功能集中于一体的单体服务,可维护性更强
- 服务彼此之间依赖服务通信的方式松耦合
- 按照业务领域来组织服务,每个团队维护各自的服务
引申出了RPC框架,比较有代表性的:
- Thrift - Facebook
- Dubbo - 阿里
- Spring Cloud
为了更好地管理服务实例,负载均衡之类的,就需要服务注册中心:
- Zookeeper
- Consul
数据库
关系型数据库(SQL)
代表就是MySQL,二维表结构,结构清晰
优点:开源、体积小、成本低,支持复杂查询
缺点:高并发支持差,海量查询慢,横向拓展支持差
非关系型数据库(NoSQL,not only SQL)
Redis:KV存储,基于分布式缓存(目前一般都是基于proxy的集群化方案,zk+codis),高性能,速度快。
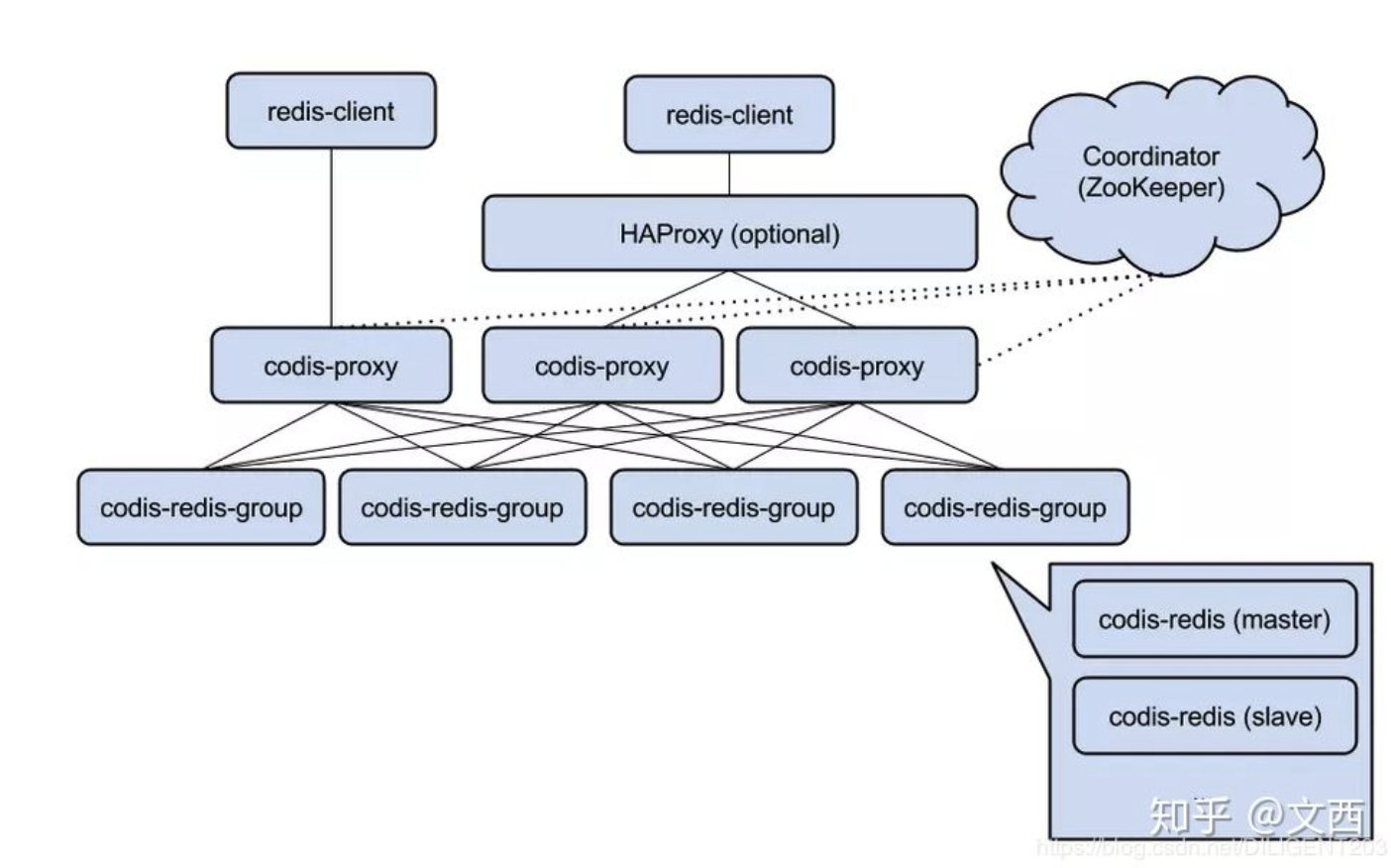
Hbase:海量数据存储,基于列式存储,row按照key - value存
Elastic Search:倒排索引,对于模糊查询,例如查询文档中的模糊词汇,MySQL -> 文档分词 -> 全量contains查询,ES则存储每个单词对应的文档。
消息队列(MQ)
伴随着业务的复杂,我们往往会遇到这个场景,一个数据操作后,需要触发下游若干个子操作。例如外卖场景,用户下订单成功,要通知商家用户订单,要物流平台对订单进行调度和派单,要触发一些后置的风控逻辑对订单合法性进行校验等。如果是同步的设计,需要在订单完成后对后续的操作一一进行API调用,这样的做法让订单流程依赖更多外部服务,提升了业务复杂度,降低了服务的稳定性,所以我们需要消息中间件来解耦操作。依赖的服务依赖下单消息,而不是在下单结束后,通过接口调用的方式触发。
我们可以把消息队列(MQ)比作是一个存放消息的容器,Producer 负责生产消息,将消息发送到MQ,Consumer取出消息供自己使用。如图所示:

Kafka
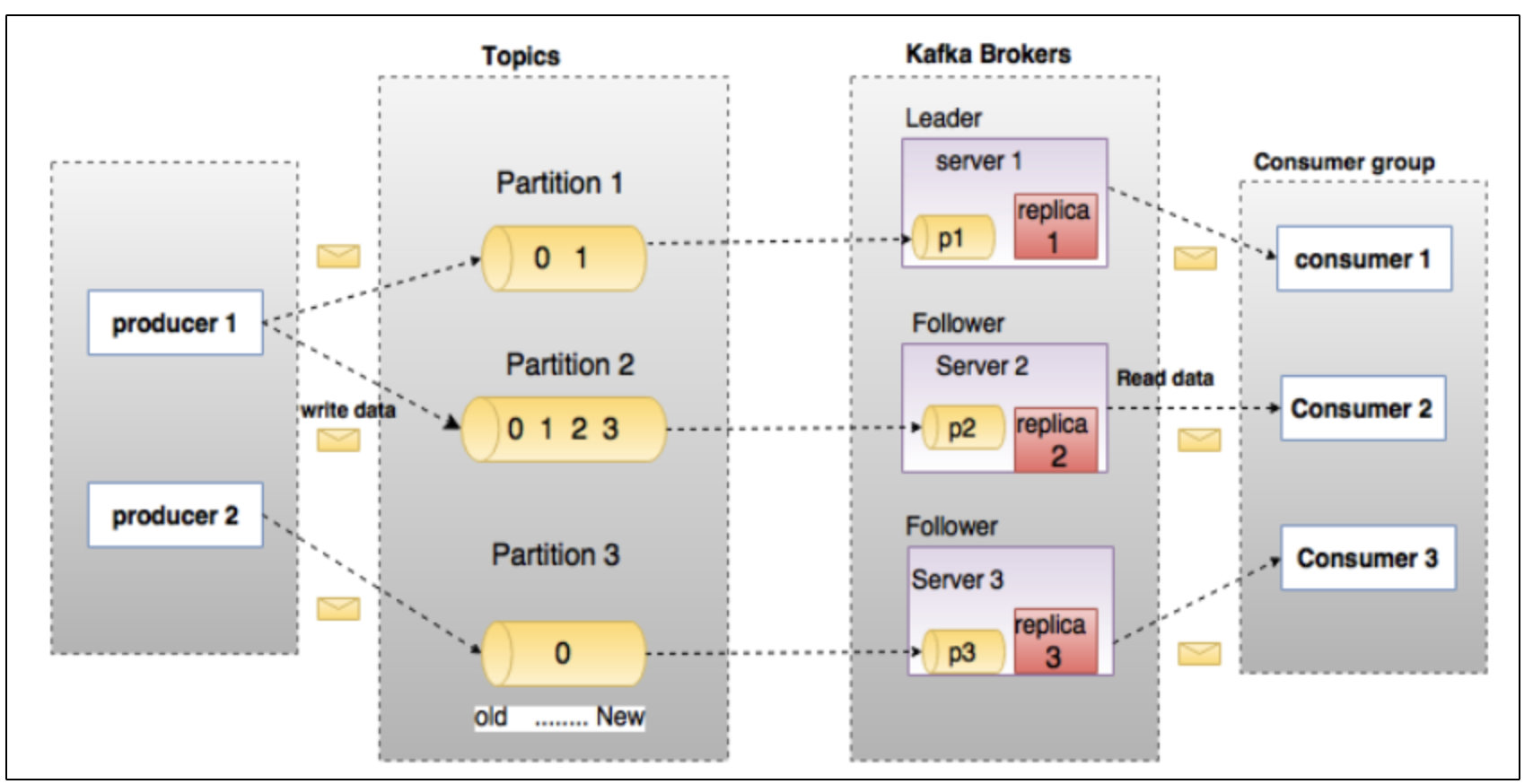
- Producer:产生topic
- Parition:topic分成不同的partition处理,每个parition里保证有序
- Replica:每个分区都有一份完整topic副本
- Broker:启动一个Kafka就是一个Broker,多个Brokder构成一个Kafka集群
- Consumer:消费任何Topic的数据,多个Consume组成一个消费者组。
通过定义producer和consumer类,启动实例和zk就可已启动kafka服务。
负载均衡
- Nginx
- Zookeeper
个人总结
- 基本上离线任务用MySQL+redis的存储方案可以cover大部分场景,实时任务用kafka做。
- 大厂会自己改造开源组件,字节有abase之类的
- 上面这些组件基本感觉都会设置一个中心调度器来管理,类似zookeeper这种,框架的共通性。
后端技术栈
http://levylv.github.io/2020/11/10/编程开发/后端技术栈/