《推荐系统实战》笔记
最近看了项亮老师的《推荐系统实践》,做了相关的心得和笔记。
一、推荐系统指标
- 用户满意度:调查问卷等方式,也可以通过线上其他指标来衡量
- 预测准确度:
- 评分预测:RMSE,MAE
- TopN推荐:准确率和召回率
- 覆盖率:物品流行度之间的差异,指标如熵、基尼系数
- 多样性:物品之间的相似性低,多样性高
- 新颖性:一般来讲,物品平均流行度低,新颖性高
- 如何在不牺牲精度的情况下提高多样性和新颖性?
- 惊喜度:与用户历史兴趣不同,但会让用户喜欢
- 信任度
- 实时性
- 健壮性
- 商业目标


二、基于用户行为分析的推荐算法
仅仅基于用户行为数据设计的推荐算法一般称为协同过滤算法,学术界对协同过滤算法 进行了深入研究,提出了很多方法,比如基于邻域的方法(neighborhood-based)、隐语义模型(latent factor model)、基于图的随机游走算法(random walk on graph)等。最终目的都是生成用户和物品之间的兴趣度。
基于领域的算法
统计方法:
- UserCF
- ItemCF

隐语义模型(Latent Factor Model)
其实本质上就是训练得到用户的隐向量和物品的隐向量(Embedding的感觉),然后再类似CTR预估。
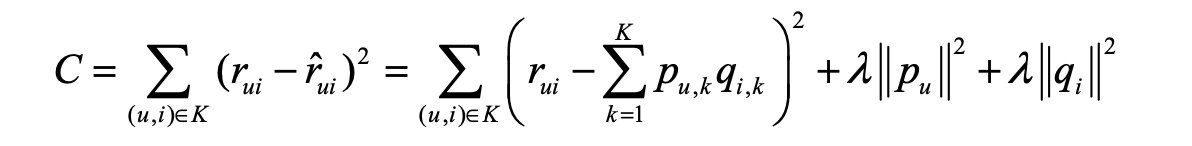
- 机器学习过程
- 离线空间复杂度较低,时间复杂度较高
- 实时性差,预测时候需要全量CTR预估再排序
- 解释性差
基于图模型
- 生成用户与物品的图,计算顶点之间的相似度
- PersonalRank,随机游走,类似马尔科夫过程,对于每个用户节点,生成所有节点访问概率,根据物品节点的概率生成推荐列表
三、冷启动问题
主要分为三种问题:
- 新用户冷启动
- 新物品冷启动
- 系统冷启动
针对新用户的冷启动
非个性化的热门推荐
利用用户的注册信息,例如年龄、性别等,做粗粒度的推荐。
- 相当于只利用用户的注册信息等特征做CTR预估。
要求用户注册填写感兴趣的领域。
- 关键是如何选取有代表性、有区分度的领域。
- 算法:做一颗决策树,选取分裂节点时,选取方差最大的物品
利用用户的社交网络,比如社交网络的好友推荐等,或者是外部网站的用户信息
针对新物品的冷启动
- 利用物品的自身内容,找计算物品相似度。
- 可能会用到文本模型,例如LSI ->PLSI -> LDA(目前主要是这个)等,来生成物品向量,并计算相似度
- 专家标注
四、利用用户标签数据的推荐算法
标签相当于用户和物品之间的媒介(有点类似topic的感觉),基于标签的推荐更加有解释性。
基于标签的物品推荐算法:
简单来讲,就是将标签作为一个隐向量来计算用户和物品的兴趣:
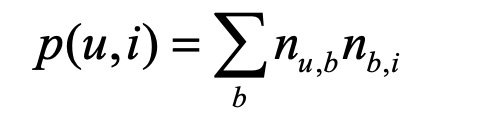
带上热门标签和热门物品的惩罚项:
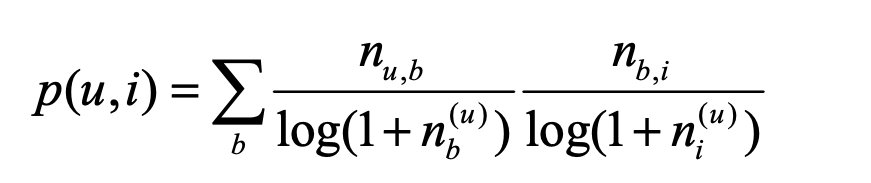
标签拓展
- 有些物品标签很少,这时候可以拓展标签,寻找相似标签。类似于itemCF的标签相似度计算方法
标签清理
- 如果我们要把标签呈现给用户,将其 作为给用户推荐某一个物品的解释,对标签的质量要求就很高。首先,这些标签不能包含没有意 义的停止词或者表示情绪的词。
基于图的标签推荐算法
利用标签作为中间层,类似于一个栅栏图。然后利用personalRank等计算节点相关性。
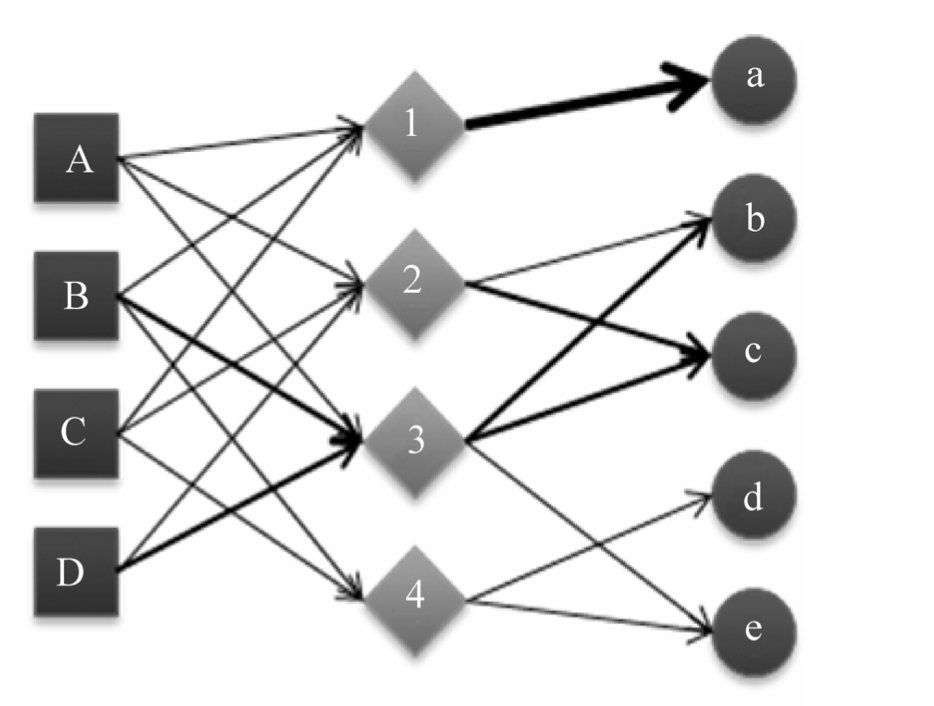
推荐打标签算法
- 用户写标签的时候给他做推荐,很多算法:用户最常打标签,该物品最热门标签等
五、利用上下文信息的推荐算法
上下文信息对用户兴趣的影响是很大的,主要代表是时间上下文和地点上下文。
引入时间上下文
可以通过统计发现,时间对对于物品流行度的影响。
推荐系统的时间多样性是很重要的(每天都有不同的推荐结果),会影响用户满意度。
如何将时间上下文引入推荐系统?几个算法:
TItemCF: 在计算物品相似度,预测用户和物品相似度时,引入时间衰减:
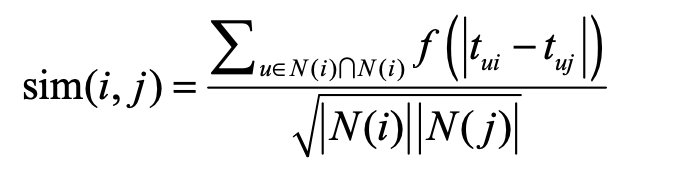
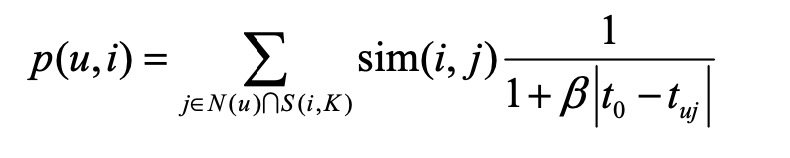
TUserCF: 也是同理:

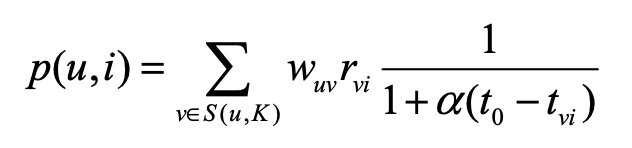
图模型:引入了时间段图模型,添加和时间有关的节点,然后再计算相关度,如果时间节点权重为0,就是普通的图。
我自己检索了下如何在CTR预估模型里引入时间上下文。阿里有个Paper, DSTN,核心思想是在特征里引入上下文广告特征,这类似得引入了时空特征。
引入地点上下文
介绍LARS算法,简单介绍一下:
对于有用户位置的数据,基于兴趣的本地性,按照不同区域划分数据集,做不同层的推荐,然后按照权重,将推荐列表线性相加:
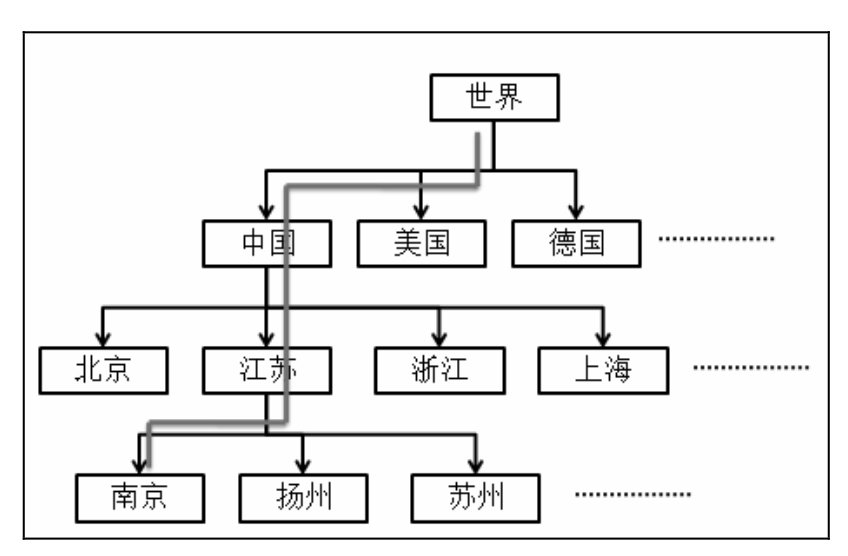
对于有物品位置的数据,在最后的兴趣得分中添加惩罚项,当前物品与用户历史物品的平均位置的距离差。
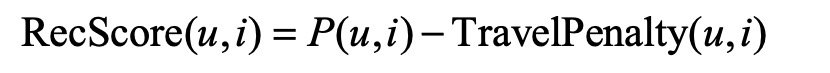
六、利用社交网络数据的推荐算法
基于社交网络的推荐
- 好友推荐增加推荐的新任务:基于社交网络的推荐不一定提升离线实验的指标,重在提升用户的信任度和可解释性。
- 可以解决新用户的冷启动问题,如前文所说
相关算法:
基于领域的社会化推荐算法
- 其实就是类似于UserCF,只是计算用户相似度的时候,不仅考虑用户兴趣相似度(通过用户历史行为),还通过社交网络考虑用户好友相似度:
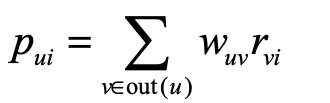
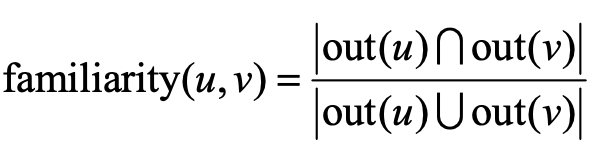
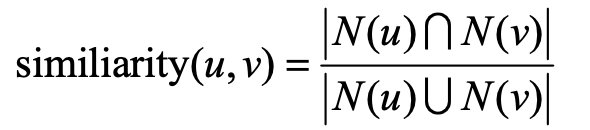
基于图的社会化推荐算法
- 就是通过社交网络增加用户与用户的边,同样可以再用personalRank。
实际系统中的社会化推荐算法
因为用户数太多,如果给用户推荐的时候,去计算所有用户的话,代价太大,两种方法:
- 只取相似度高的N个用户
- 设计一种特殊的数据存储结构:每个用户维护一个消息队列,其他相关用户产生一个物品行为,则在消息队列中添加该物品。这样的话,推荐计算的时候,只需读取自身的消息队列,然后通过队列里物品的相关信息来算即可。
社交网络好友推荐
其实就是计算用户与用户之间的相似度,还是可以通过兴趣相似度和好友相似度来做。
七、推荐系统实例
一个真实的推荐网站有三部分组成:
推荐系统
前端页面:需要展示推荐物品的相关信息,推荐理由,用户反馈设计
日志系统:不同的用户行为,有不同的规模大小和实时性需求,可能需要不同的数据存储结构

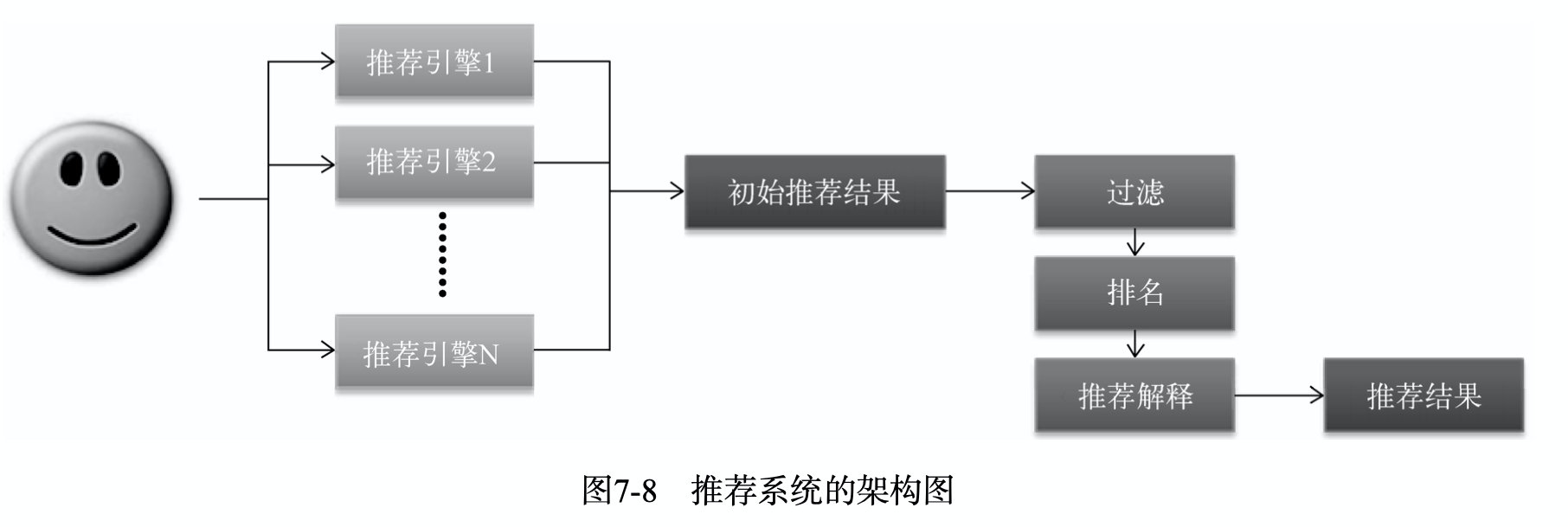
一个推荐系统的组成:
- 由不同的推荐引擎构成,来处理不同的推荐任务,比如个性化推荐、新颖性推荐、最新物品推荐等等
- 由推荐系统再过滤、排名、解释等汇总组合各个推荐引擎结果。
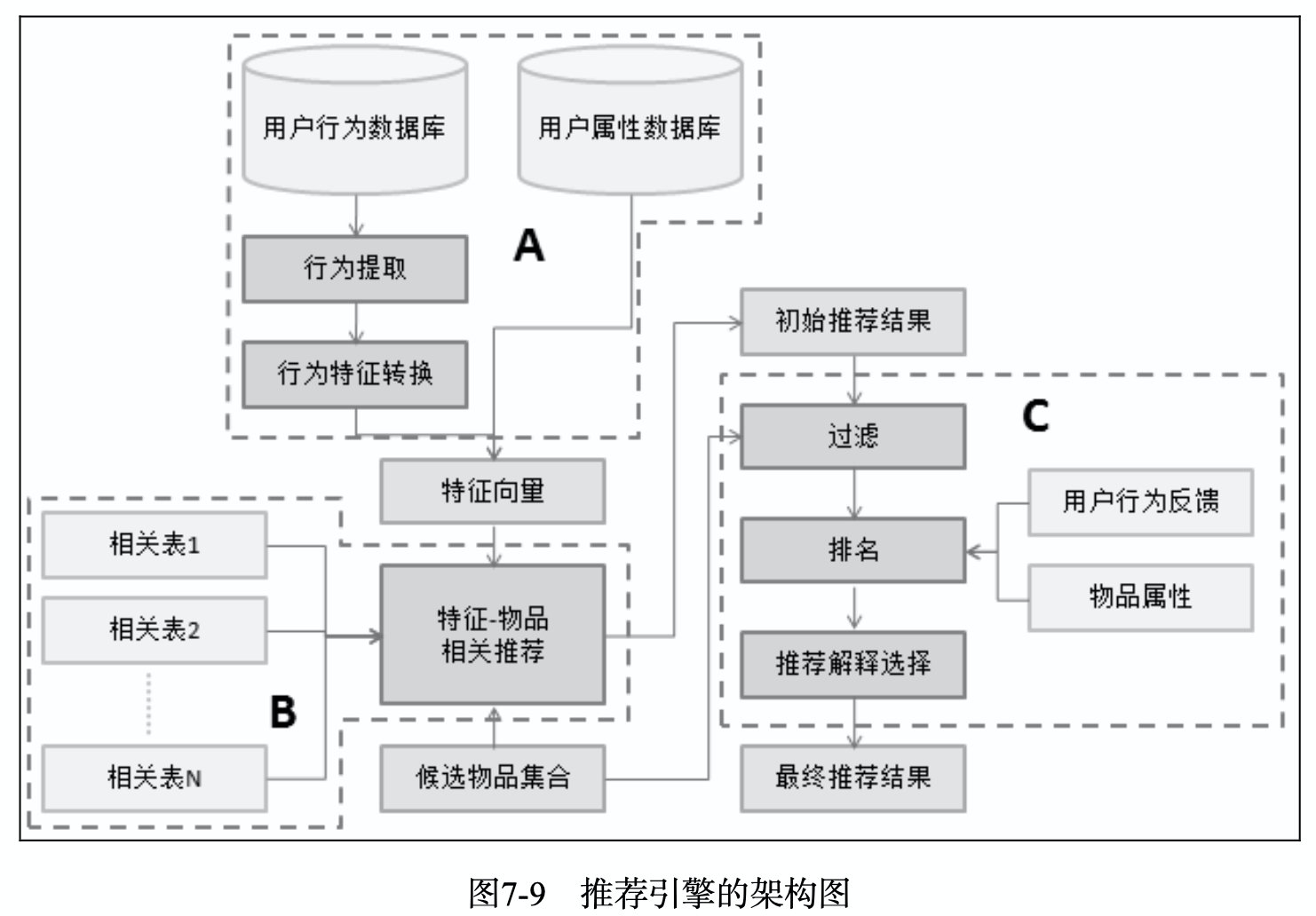
一个推荐引擎的架构,主要三部分:
- 用户特征提取模块
- 特征-物品推荐模块:也俗称召回模块,就是本书介绍的算法模型。
- 对初始的推荐列表进行过滤、排名等处理,从而生成最终的推荐结果。排名模块里涉及到了CTR预估模型,也俗称精排模块。
重点聊下排名模块:
- 这个终于让我知道了CTR预估模型在推荐系统里的作用!之前一直以为CTR预估模型也是类似CF等算法,但其实不是,CTR预估模型是针对推荐结果的精排,想想也是,只有推荐结果的点击才有真实的正负样本可以来训练!前面的召回模型哪来的负样本呢..用户没购买,并不意味这不喜欢物品啊。同时CTR预估模型也是计算广告系统非常重要的模型!CTR值直接影响了预算收益等。
- 排名模块包含很多:
- 新颖性排名:通过基于物品流行度来降低热门物品的权重
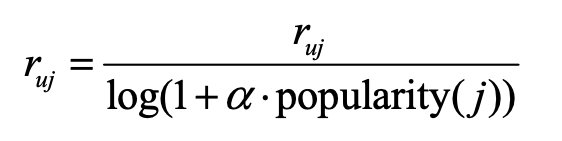
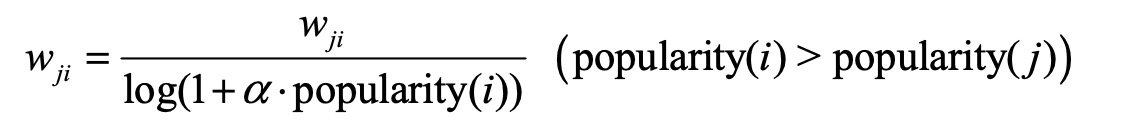
- 多样性排名:1. 对物品按内容分类,不同类目分别取物品 2. 对相同推荐理由的物品进行降权采样
- 时间多样性:对于之前推荐过的物品进行降权采样
- 用户反馈:排名模块最重要的部分。通过用户反馈拿到正负样本,用CTR预估模型,特征有:

八、评分预测问题
评分预测算法介绍:离线评测指标RMSE/MAE
- 平均值相关
- 基于领域的方法,就类似UserCF,只是把r=1换成得分:
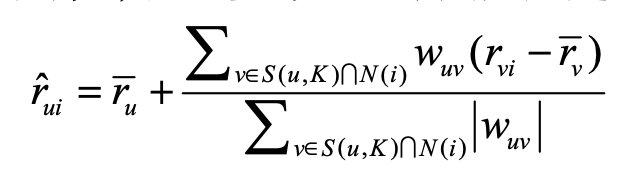
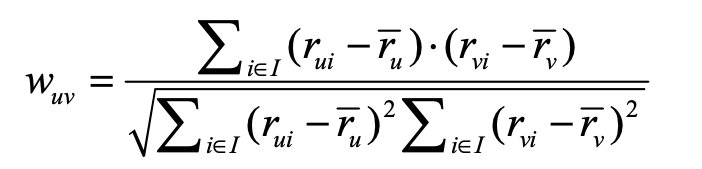
- 隐语义模型与矩阵分解模型:
- SVD分解,取top k,再进行SVD计算,得到评分矩阵。缺点:SVD用户和物品的维度太大高,计算量太大
- LFM,通过梯度下降求解SVD的隐向量,换发新春。
- 加入时间信息
- 基于邻域的模型融合时间信息:同之前TItemCF,TUserCF
- 基于矩阵分解的模型融合时间信息: 加入时间项
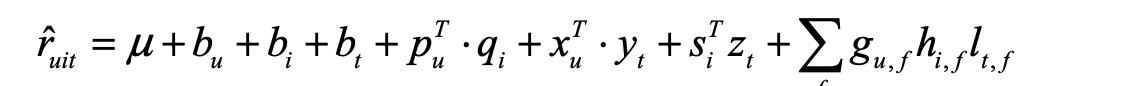
- 模型融合:
- 模型级联融合:同adaboost
- 模型加权融合:同stacking
结语:推荐系统十堂课
- 确定你真的需要推荐系统
- 确定商业目标和用户满意度之间的关系
- 选择合适的开发人员
- 忘记冷启动的问题
- 平衡数据和算法之间的关系
- 找到相关的物品很容易
- 不要浪费时间计算相似兴趣的用户,可以直接利用社会网络数据
- 需要不断地提升算法的扩展性
- 选择合适的用户反馈方式
- 设计合理的评测系统,时刻关注推荐系统各方面的性能