《自然语言处理入门》笔记
疫情期间看完了何晗老师的《自然语言处理入门》这本书,真的是学习了很多NLP的传统知识,本文是相关的笔记。
何晗老师的博客:码农场
一、新手上路
NLP相关任务
最基本的工具任务:词法分析:(中文)分词,词性标注和命名实体识别
信息抽取
文本分类与文本聚类
句法分析
语义分析与篇章分析
更高级任务:机器翻译、问答系统等
语料库
- 中文分词语料库:
- 1998《人民日报》,PKU语料库
- 微软亚洲研究院,MSR语料库
- 香港城市大学,CITYU语料库-繁体中文
- 台湾中央研究院,AS语料库-繁体中文
- 词性标注:
- 1998年《人民日报》,PKU标注集
- 国家语委语料库,863标注集
- CTB(中文树库)语料库,CTB标注集
- 《诛仙》语料库,CTB标注集
- 命名实体识别:
- 1998年《人民日报》,实体:人名/地名/机构名
- 微软亚洲研究院,实体: 专有名词/时间表达式/数字表达式/度量表达式/地址表达式等5大类30个子类
- 句法分析
- CTB语料库
- 文本分类
- 搜狗文本分类语料库,8000篇新闻
开源工具
- NLTK
- 斯坦福大学CoreNLP
- 哈工大LTP
- HanLP
二、词典分词
总体思想
基于词典进行分词,分词算法包括:
- 完全切分
- 最大正向匹配
- 最大逆向匹配
- 双向最大匹配
存储和计算效率
为了提升存储和计算效率,提出了词典的四种数据结构:
- 字典树
- 双数组字典树
- AC自动机
- 基于双数组字典树的AC自动机
其他应用
- 停用词过滤
- 简繁转换
- 拼音转换
总体而言,字典分词的缺点是无法解决歧义和OOV问题。
三、二元语法与中文分词
- 提出了语言模型,来解决歧义问题,例如分别计算“商品 和 服务” 与 “商品 和服 务”的概率,选择概率大的一种分词。
- 如果用假设为一阶马尔科夫过程,则为二元语法模型。
- 模型训练:统计词频,计算二元概率
- 模型预测:
- 词语全切分
- 生成词网图
- 维特比译码,其实就是动态规划,每个上游节点都保存最短路径。
- 缺点:还是无法解决OOV问题
四、隐马尔科夫模型与序列标注
- 正式提出了序列标注思想,对于分词任务而言,就是设置{B、M、E、S}标注集,作为隐状态,而字符就是显状态,也称观测状态。
- HMM由{初始概率矩阵,状态转移矩阵,发射矩阵}三部分组成。
- HMM是生成模型,因为计算的其实就是f(x,y)的联合概率,只是用马尔科夫过程简化为了初始概率矩阵 状态转移矩阵 发射矩阵。
- 模型训练:
- 显状态和隐状态都已知,直接计算词频,统计概率。
- 显状态已知,隐状态未知,需要用EM算法。
- 模型预测:
- 理论上是遍历所有y,计算最大概率的y,复杂度高。
- 维特比译码,即动态规划,每个时刻的每个状态保留最大概率路径。
- 可以解决OOV,但是还是不够好,jieba分词就是用的HMM
五、感知机分类与序列标注
感知机算法
模型预测:公式为 $y = sign(wx + b)$
模型训练:对于每一个训练样本:
- 如果预测$\hat{y}$与真实$y$相等,则跳过
- 如果不相等,则$w = w + x * y$
其实相当于损失函数为
每次迭代的感知机参数都保留,做集成:
- 投票感知机:每个感知机结果加权平均
- 平均感知机:每个感知机的参数直接求平均
结构化感知机算法
属于结构化预测问题,例如机器翻译、序列标注等,预测结果诸如是一个序列、一颗树啊等等。此类算法往往在训练的时候,就需要做预测的工作。
定义得分函数$score(x,y) = w.\phi(x, y)$,其中$\phi(x,y)$就是特征函数,则$\hat{y} = argmax \ {score(x,y)}$
模型属于判别模型,因为最终归一化后,其实还是条件概率$p(y|x) = \frac{exp(score(x,y))}{\sum_{y}{exp(score{(x,y))}}}$,其Loss Function是
模型训练:对于每一个训练样本,先预测$\hat{y} = argmax \ w.\phi(x, y)$,然后对于正确的y进行奖励,对于错误的预测$\hat{y}$,进行惩罚,最终w的更新公式为
模型预测:同样是维特比译码。
特征提取问题:
特征函数取值0或1 ,一般分为两类:
- 转移特征,$f(y{t-1}, y{t})$ ,只跟状态值有关,N种状态的话,取值就只有$ N * (N+1)$,因为包含了初始状态BOS。
- 状态特征,$f(y{t}, x{t})$,只跟当前隐状态值和显状态有关。
一般是基于特征模板生成所有特征,特征模块如:
转移特征模板,$y_{t-1}$
状态特征模板,$x{t-1}, x_t, x{t-2}/x{t-1}, x{t-1}/x_{t}$
六、条件随机场与序列标注
首先阐述概率图模型,概率图分为两种:
- 有向概率图:联合概率密度$p(x,y) = \prod{p(v | \pi(v))}$,$\pi(v)$表示v的所有前驱节点
- 无向概率图:联合概率密度可以分解为所有最大团的某种函数之乘积,所谓最大团,就是团内每个节点互相连接。还可以定义虚拟的因子节点,因子节点只连接两个相邻节点,组成最小的最大团,那么联合概率密度就是所有因子节点之积:
这样的话,
条件随机场,就是给定输入随机变量x,求解条件概率$p(y|x)$的概率无向图。用于序列标注时,就是线性链条件随机场:
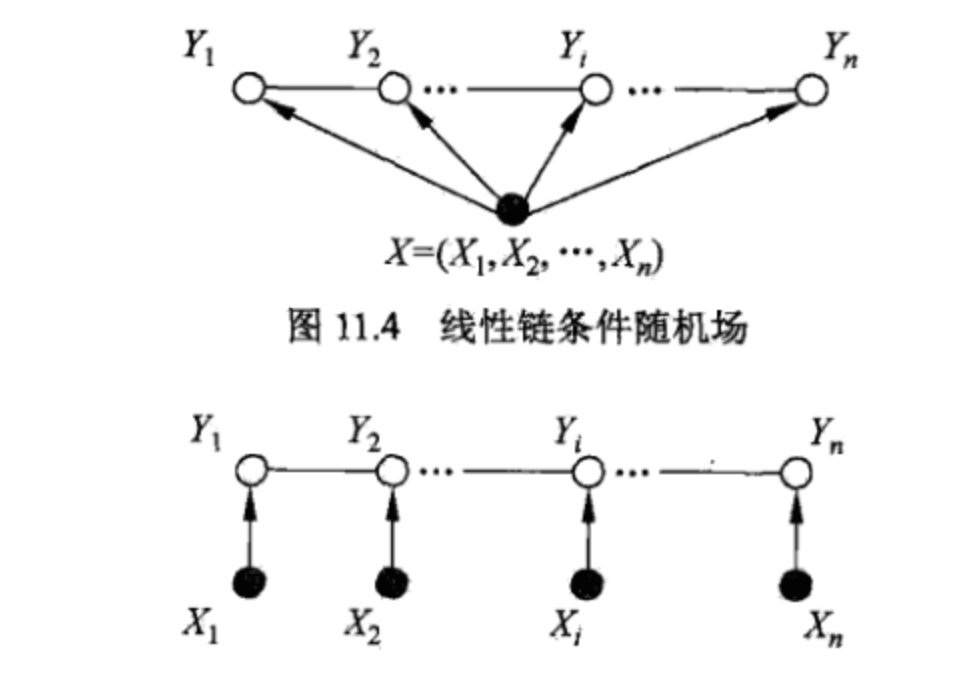
如果用虚拟因子的话,显然就只有两类因子:
- 转移因子,发生在$yt$和$y{t-1}$之间,即转移特征函数
- 状态因子,发生在$y_t$和$x_t$之间,即状态特征函数
如果某种函数定义为$w.\phi(yt,y{t-1},x_t)$之后,其实就和结构化感知机一模一样了:
条件随机场的预测:
- 和结构化感知机一样,都是维特比译码
条件随机场的训练:
训练和结构化感知机不一样,因为条件随机场的Loss Function为最大似然概率,即也相当于最大(相对)熵:
利用梯度下降法求解的话,w参数更新公式(和结构化感知机最大的区别就在这里):
- 感知机仅惩罚错得最厉害的哪一个$\hat{y}$对应的特征函数$\phi(x,\hat{y})$
- 条件随机场惩罚所有答案,总惩罚量依然为1,但是所有答案分摊,而当特征函数的经验分布期望和模型期望一致的时候,梯度为0,不需要再更新。
- 条件随机场其实就是最大熵模型的衍生~可以看我之前的有关最大熵模型的博文。
七、词性标注
本质上也是一个序列标注模型,标注方式有两种:
- 独立模型:先进行分词任务,再进行词性标注任务,流水线。
- 联合模型:将分词任务和词性任务联合,标注集例如{B-名词,M-名词}等。
- 优点:联合模型几乎在所有问题上优于独立模型。
- 缺点:很难有同时标注分词和词性的优秀语料库,一般而言中分分词语料库远多于词性标注语料库;还有就是,联合模型的标注集很大,导致特征数量也很大,参数爆炸。
八、命名实体识别
- 同样是个序列标注模型,标注集{BMES-实体,O}。但命名实体识别任务,往往可以统计为主、规则为辅。
- 对于规则较强的命名实体,例如网址、E-mail、ISBN、商品编号等,完全可以通过正则表达式先进行预处理提取,再分词统计
- 对于较短的命名实体,例如人名,完全可以通过先分词,再词性标注即可。
- HanLP对于一些命名实体是用规则来做的:
- 音译人名
- 日本人名
- 数词英文实体:这个被称为原子分词,这个代码非常值得学习。
- 自定义领域的命名实体识别任务
- Step 1:收集生语料
- Step 2:可以先利用HanLP的词法分析器,得到分词和词性标注结果
- Step 3:基于词法分析结果,人工标注你想要的实体,生成熟语料
- Step 4:训练序列标注模型
九、信息抽取
所介绍的都是无监督算法。
新词提取
从文章中发现新的词汇,信息熵算法:
- 如果一个字符串左边和右边的搭配很丰富,并且字符串本身的字符搭配很固定,这大概率就是个词汇。
- 信息熵:计算某个字符串左边和右边单个字符的信息熵,设定信息熵>=某个阈值
- 互信息:计算该字符串内部的所有字符之间的互信息,互信息大,说明字符都是相关的,设定互信息>=某个阈值
- 取符合上诉要求的词频Top N字符串。
短语提取
与新词提取相同,只是需要先进行分词,然后把:
- 字符串 -> 单词列表
- 左右的单个字符 -> 单个单词
关键词提取
- Top N词频
- Top N TF-IDF :单词在本文档的词频 / 单词出现在所有文档的次数
- TextRank:类似pageRank,基于网站之间的链接生成图,然后每个节点的权重取决于指向该节点的所有子节点,但是其他子节点的权重计算的时候会因为它指向的节点个数而减少。权重逐步迭代,最终稳定。而文本的话,就是用滑动窗口,中间单词和附近单词产生链接。
关键句提取
类似关键词提取,但有个TF-IDF的变种-BM25。
十、文本聚类
生成文档向量
- 词袋模型:说白了就类似one-hot,只是值换为词频。
- 布尔词频:就是one-hot
- TF-IDF:就值换为tf-idf值
- 词向量:word2vec,然后所有词向量求和
- 自编码器:输入时词袋,文档向量就是中间的隐层向量
聚类算法
K-means算法,但是k-means有非常多的改进方法:
- 朴素k-means:
- 随机选取k个初始质心 -> 分配簇 -> 重新计算质心 -> 重复
- 初始质心选取改进:先选取一个质心,然后再选取一个其他的点,如果其和最近质心的距离能够减小准则函数,再将其变为质心,以此类推,每一步都保证了准则函数的减小。
- 更快的准则函数:将欧式距离改为余弦距离:
- 随机选取k个初始质心 -> 分配簇 -> 对每个点,计算将其移入另一个簇时准则函数的增量,找出最大量并移动 -> 重复
- 层次聚类:刚开始一个簇,然后k-means分成两个,以此类推,保证二分后准则函数的gain增大,可以自动判断聚类个数。
十一、文本分类
大致思想也很简单:
分词,提取单词;这一步并非必须,清华有个研究表明,直接提取所有相邻的n元字符,效果更好。
提取特征:词袋向量。缺点是无法表征词语之间顺序,如“不 优秀” 和 “优秀 不”。
- 特征筛选:利用卡方校验判断特征与类别之间的独立性,其实思想比较类似IV值。
- 分类模型:朴素贝叶斯、SVM等
十二、依存句法分析
在词法分析之后,语法分析是NLP的重要一环,也是较为高级、较为复杂的一种任务。
短语结构树
上下文无关语法/短语结构语法:句子通过语法结构生成。比如上海+名词短语 -> 上海 + 浦东 + 名词短语 -> 上海 + 浦东 + 机场 + 航站楼。
短语结构树:短语结构语法描述如何自顶而下生成一个句子,句子也可以通过短语结构语法来递归分解,最终生成一颗树结构。
英文树库:宾州树库PTB,中文树库:CTB。词性标注集:CTB。
20世纪90年代大部分句法分析都集中在短语结构树,由于其较为复杂,准确率并不高
依存句法树
- 词与词之间存在主从关系,如果一个词修饰另一个词,那么称修饰词为从属词,被修饰词为支配词,两者之间的语法关系称为依存关系。比如 “大梦想”中 ,“大” 修饰 “梦想”,定中关系。
- 依存句法树4个公理:
- 有且只有一个root虚拟根节点,不依存其他词语
- 除此外所有单词必须依存于其他单词
- 每个单词不能依存多个单词
- 如果单词A依存B,那么位置处于A和B之间的单词C只能依存于A、B或AB之间的单词
- 开源自由的依存树库:UD(Universal Dependencies),树库格式为CoNLL-U;CTB语料库,可以从短语结构树转化为依存句法树。
- 输入是词语和词性,输出是一颗依存句法树,算法有两类:
- 基于图的依存句法分析:提取特征,为每条边是否属于句法树的可能性打分,然后用最大生成树作为依存句法树。缺点:开销很大
- 基于转移的依存句法分析:将树的构建过程拆分为一系列转移动作,所以只需利用自己的状态和输入单词来预测下一步要执行的转移动作,最后根据动作拼接依存句法树。
- Arc-Eager转移系统:定义状态集合和转移动作
- 训练:结构化感知机
- 预测:柱搜索。全局最优转移路径理论上可以通过一些动态规划(如维特比)一样来实行,但是路径过长、分支过多,在计算上不可行,因此用柱搜索:每个时刻仅仅维护分数最高的前k条子路径,k又称柱宽。
十三、深度学习与自然语言处理
传统方法的局限
- 数据稀疏,无穷多的单词,one-hot编码维度巨高且稀疏 -> 深度神经网络将其化为稠密向量,相似度也会体现出来
- 特征模板,需要自己设计,且特征非常稀疏 -> 深度神经网络利用多层感知器特征交叉,自动提取特征表示。
- 误差传播,例如情感分析任务:先分词、再词性标注、再SVM,多个模型的误差传播 -> 深度神经网络,直接输入字符的one-hot向量,输出分类结果,端到端
Word2Vec
- CBOW:输入:上下文,输出:中心词
- Skip-Gram:输入:中心词,输出:上下文
- 更详细的介绍,可以看我之前的博客word2vec详解
自然语言处理进阶
两个常用的特征提取器:RNN和CNN
- RNN,可以处理变长的输入,适合文本。特别是LSTM,可以记忆约200左右的单词。缺陷在于难以并行化。如果句子相对较短,所以在句子颗粒度上进行的基础NLP任务(中文分词、词性标注、命名实体识别和句法分析)经常用RNN
- CNN,可以捕捉文本中的n元语法,可以并行化,考虑到文档一般较长,许多文档分类模型都是用CNN。
词向量的研究:
- Fackbook-fastText,可以得到任意词语的向量,不要求词语一定出现在语料库
- ELMO,解决一词多义,需要读入上文才才可以预测当前单词的词向量
- Google BERT模型通过一种高效的双向transformer网络同时对上下文建模
- 基于线性模型的标注器被BiLSTM-CRF等取代
- 其实BiILSTM+CRF模型的话,就是用BiLSTM来提取状态特征f(xi, yi),用CRF只提取转移特征。
- 句法分析器-BiAffineAttention
- QA任务,归结为衡量问题和备选答案之前的文本相似度,恰好是具备注意力机制的神经网络擅长的。
- 文档摘要涉及的文本生成技术,恰好是RNN擅长的。
- 机器翻译领域,Google早已利用基于神经网络的机器翻译技术。学术界目前流行的趋势是Transformer和注意力机制提取特征。