Spark名词相关理解
关于partition和task
partition是spark RDD的操作单元,通常会把一个数据集切分成若干个partition,实现并行处理。我把它称之为需求。
task则是机器能提供的操作单元,一个core对应一个task,一个task处理一个partition。我把它称之为供给。
所以,如果stage还是只有2个partition,无论怎么调节executors的资源数目,都是没有用的,active task也只有2个而已!
关于调节partition,又分为两类:
非spark sql操作
- spark.default.parallelism 集团没有默认值
这个参数控制RDD的partition数目,但是只对于Spark SQL以外的所有Spark的stage生效,无法控制spark sql生成的分区。Spark SQL的并行度不允许用户自己指定,Spark SQL自己会默认根据hive表对应的HDFS文件的split个数自动设置Spark SQL所在的那个stage的并行度。
然而,我们平时用到的大部分操作都是spark sql的操作,为方便后续的复杂逻辑处理,最后sql取数之后repartition处理成多个分区。
spark sql操作
a. 普通的操作可以用repartition来做。
b. 对于shuffle操作,也是最常见的操作,例如join, group等。
- spark.sql.shuffle.partitions 集团默认是1000个
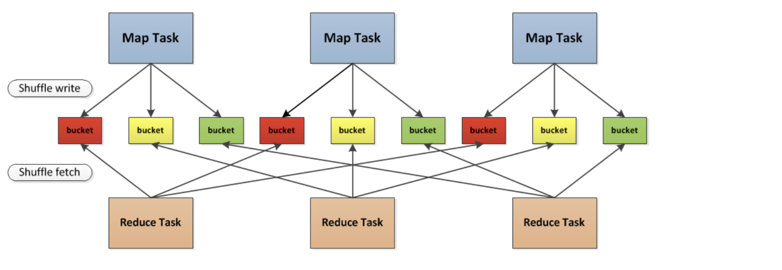
控制的是每个mapper端写出的partition个数,其实也就是reducer的个数,并不是mapper的个数。例如group by a,那么在每个mapper里按照a的值分成1000个partition数,写到磁盘,启动1000个reducer,每个reducer从每个mapper端拉取对应索引的partition。 - spark.sql.adaptive.enabled
是否开启调整partition功能,如果开启,spark.sql.shuffle.partitions设置的partition可能会被合并到一个reducer里运行。默认开启,同时强烈建议开启。理由:更好利用单个executor的性能,还能缓解小文件问题。 - spark.sql.adaptive.shuffle.targetPostShuffleInputSize
和spark.sql.adaptive.enabled配合使用,当开启调整partition功能后,当mapper端两个partition的数据合并后数据量小于targetPostShuffleInputSize时,Spark会将两个partition进行合并到一个reducer端进行处理。 - spark.sql.adaptive.minNumPostShufflePartitions
当spark.sql.adaptive.enabled参数开启后,有时会导致很多分区被合并,为了防止分区过少,可以设置spark.sql.adaptive.minNumPostShufflePartitions参数,防止分区过少而影响性能。
调优例子
我明明设置了minNumPostShufflePartitions参数,但是我发现某个涉及shuffle操作stage(A join B 得到C, C join D)的始终只有2个parition!
解决方案:这个问题原因应该是shuffle后的C导致,因为A join B的关联key值过少,远远小于minNumPostShufflePartitions这个值,导致reduce后C的partition只有2个,从而使得后面C join D的时候,mapper数也只有2个。只加了一句C.repartition(200)后问题就解决了。。
关于MapReduce的shuffle过程和Spark的shuffle算子
Hadoop是MapReduce框架,任何一个MapReduce过程都分为Mapper(程序员编写), Shuffle和Reduce(程序员编写)过程。最影响性能的就是shuffle,因为涉及到key值排序,网络传输等。
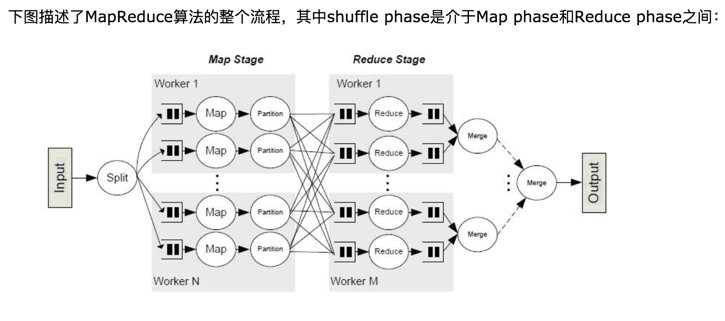
对于spark而言,只有两类操作,包括transform操作(从一个RDD到另一个RDD)和action操作(RDD变为结果值返回),任何操作都是由partition构成,以典型的shuffle算子为例,其实也类似与mapper(mapper数即为partition数)和reduce(reduce数即为partiton数)过程。但是更吊的是,在mapper task里直接进行了partition,后续reduce只要按照索引从每个mapper里取对应索引的partition就好了。