类别不均衡问题的调参
对于类别不均衡问题,处理方法有:
正样本过采样
负样本降采样
调整阈值
主要是这三种,实际算法处理过程往往是这样的:
先对负样本进行降采样or正样本过采样来提取训练样本,以保证模型的AUC尽量高。
过采样or降采样之后模型输出的概率已经失去原本的意义,所以在测试集上如果看其他评价指标如交叉熵,那loss是很大的,当然不影响AUC。所以,我们需要对输出概率再做调整,恢复到真正实际的概率值。
实际样例:
CTR预估模型之GBDT+LR:对负样本进行以w频率进行降采样,然后对预测概率值重新调整:(AUC只保序,通过calibration校正概率阈值)
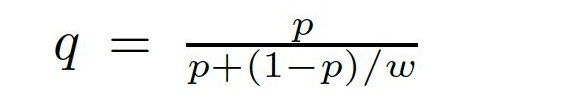
Xgboost:设置了scale_pos_weight参数,该参数的合理值= 负样本数/正样本数,该参数的意义是让正样本梯度(也就是loss)的权重值变大,也就是更加关注正样本的loss,有点类似于正样本的过采样。scale_pos_weight只适用于AUC,也就是只适用于将样本进行二分类,最终概率值并非真实概率值。
关于Weighted LR中正样本过采样还是正样本梯度加权重这两种方式:
这两种训练方法得到的结果是不一样的,比如要抽样10倍,对于第一种方法,就是把一条样本重复10倍,这样优化的过程中,每遇到一条这个样本,就会用梯度更新一下参数,然后用更新后的参数再去计算下一条样本上的梯度,如果逐步计算并更新梯度10次;但对于第二种方法,则是一次性更新了单条梯度乘以10这么多的梯度,是一种一次到位的做法。
直观一些来讲,第一种方法更像是给予一条样本10倍的关注,愿意花更多时间和精力来对待这条样本,是一种更细致的方法,第二种则比较粗暴了,不愿意花太多功夫,直接给你10倍权重。
类别不均衡问题的调参
http://levylv.github.io/2019/04/24/机器学习/类别不均衡问题的调参/