Spark调优以及各名词深刻理解
Spark资源优化:
队列是根据Fair调度分配资源的。
静态资源分配方式的问题:
- stage非对称
- Task非对称-数据倾斜
- 执行时间随意性
所以需要根据任务动态分配资源。例如:
Executor资源量相关:
spark.dynamicAllocation.minExecutors
spark.dynamicAllocation.maxExecutors
这个就会让任务根据资源需求而自动调整executors。
遗留参数
spark.executor.instances — 这个参数是老版本的,静态资源分配,不要用了。
Spark内存优化:
内存模型(heap就是工作用的可用内存,超过了就OOM,滴滴NodeManager指定了不超过15G,超过了就被yarn killed)

统一内存模型:(可用内存 = 统一内存+其他,统一内存= 存储内存+计算内存)

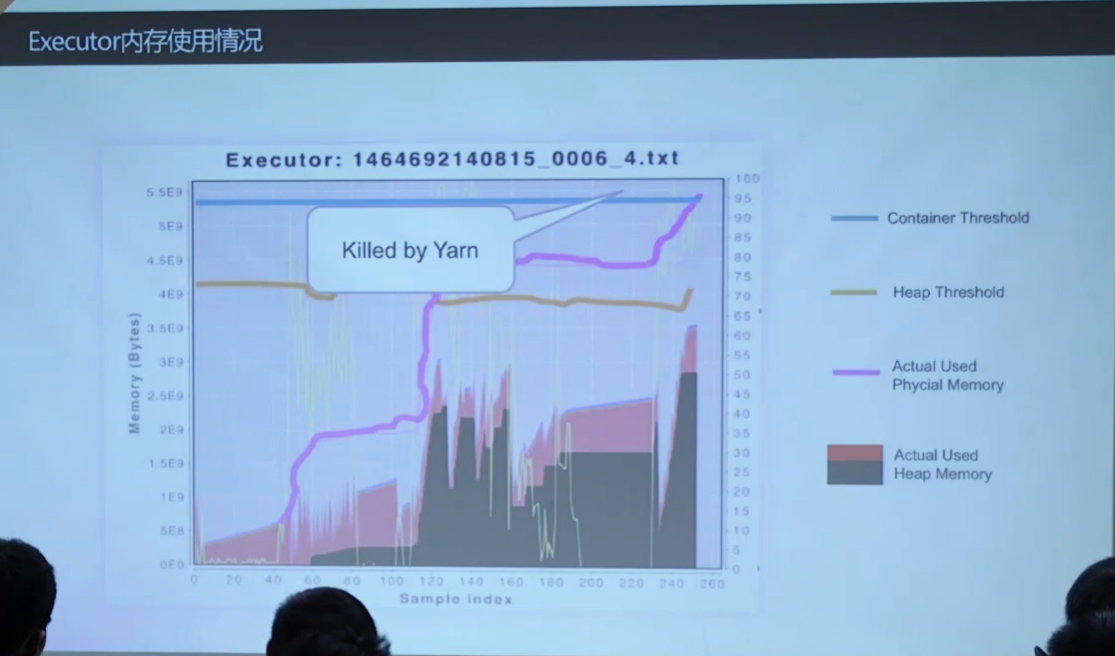
acutal used大于heap memory:因为还有overhead的开销
常见异常1:
- Executor OOM(具体其实是executor中的task超出了heap内存)
- heap内存不够,TASK需要更多内存(task是在这个executor上的任务,最低保障是 1/2n)
- 解决思路
- 增加单位Task的内存可用量
- 增加heap的值:spark.executor.memory (java -Xmx)
- 减少单个executor的task数,即减少n,spark.executor.cores
- 减少单位Task的内存消耗量
- 增加partition,降低Task处理的数据,增加spark.default.parallism或者spark.sql.shuffle.partition(sql应用)
- 调整应用逻辑,降低内存使用
- groupByKey -> reduceByKey
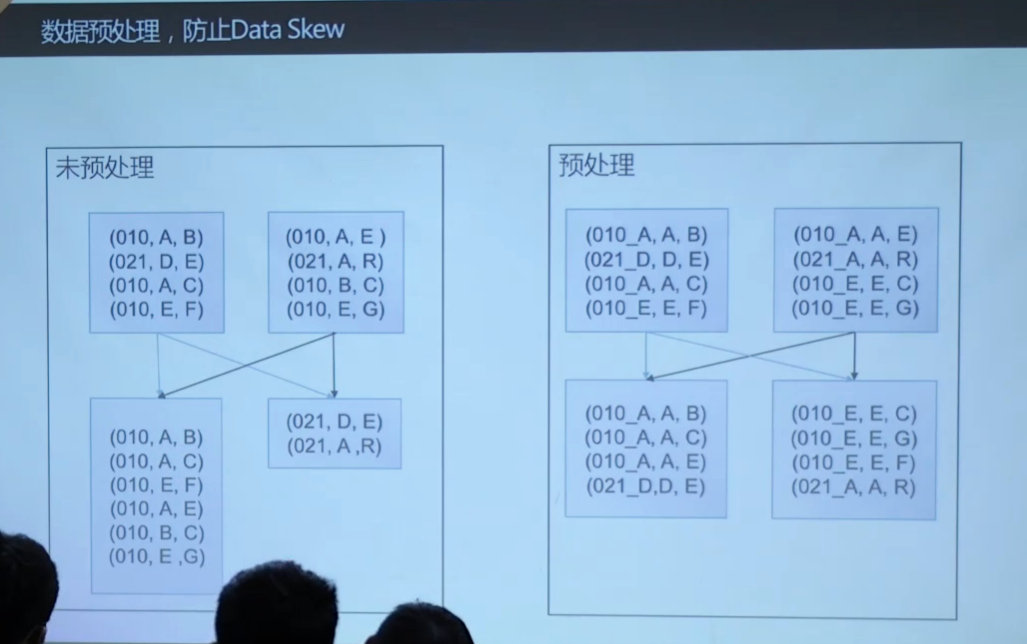
- 数据预处理,降低倾斜
- 增加单位Task的内存可用量

常见异常2:
- killed by yarn
- Executor不存在子进程
- yarn监控到的container的内存为JVM内存
- 此时,killed by yarn为JVM非堆内存不足所致,也就是超过了overhead设置的内存
- 调整方案
- 增加overhead量
- spark.yarn.executor.memoryOverHead
- scala或者java应用,默认2G能满足需求
- 减少cores,也就是减少n
- 增加overhead量
- Executor存在子进程
- container监控内存=executor内存(E) + 子进程内存(S)
- 子进程对内存资源的占用会压缩E
- 典型场景
- PySpark, JVM + PVM
- 调整方案,增加overhead量
- Executor不存在子进程
Spark Shuffle优化:
shuffle挑战:

I/O优化:

避免shuffle的broadcast hash join
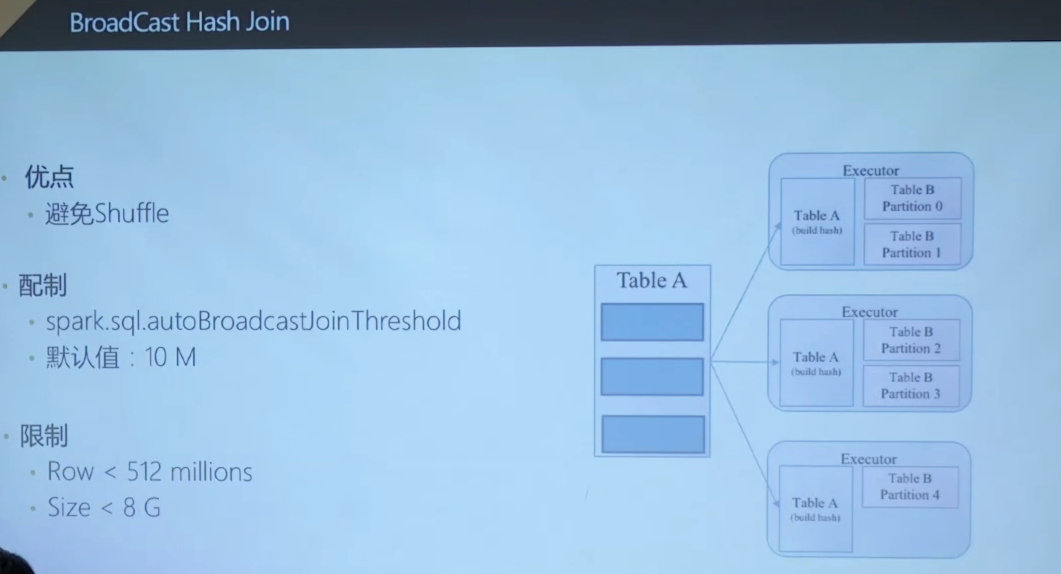
缺点:很耗driver内存,例如16M的broadcast的数据,耗费100M的driver内存。
CBO是优化join时候的build表的,从而达到各种broadcast join / shuffle hash join(先shuffle,再broadcast)的目的, sort merge join就是我们目前经常用的。

默认不开启是为了driver内存考虑,下次可以尝试开启试一下。
Spark调优以及各名词深刻理解
http://levylv.github.io/2018/11/28/大数据/Spark/Spark性能调优/